C语言近几十年增加了一些“新特性”
发表于: 2019-10-03 11:08:13 | 已被阅读: 373 | 分类于: C语言
基本上,每一个程序员都知道使用C语言可以写出可移植的程序。所谓“可移植”,无非就是在不同的设备平台,程序能够表现一致,具有相同的功能。
C语言标准
C语言代码是不可以直接被机器执行的,它在被执行之前,必须被编译器“翻译为”机器指令。一般来说,不同的设备平台上的C语言编译器在实现上都是有所差异的,为了确保这些“有差异”的编译器处理同一份C语言代码时,能够实现相同的功能,必须制定相应的标准,即所谓的Cxx 标准。
C语言这几十年来也是有所发展的,从前些年的C89标准到C90、C99,以及C11标准,C语言多多少少也增加了许多“新特性”。
事实上,C99标准已经推出20年了,但是对它的支持却来得很慢,所以即使在C11标准都已经推出的今天,相当多的C语言程序员依然在使用C89标准提供的C语言特性,因此在一些开源C语言代码中看到C99特性时,他们常常会感到惊讶。
现在大多数主流C语言编译器都已经支持C99,我觉得作为C语言程序员,应该知道C99标准中新增的一些比较好用的C语言“新特性”。当然了,本文不可能将所有的“新特性”一一列举,这里我仅将我个人认为一些比较好用的特性列出,希望能够抛砖引玉。
for()内部的变量声明
在C++程序开发中,程序员需要使用 for() 循环语句时,常常将循环遍历定义在 for() 内部,请看:
for (int i = 0; i < n; ++i) { ... }这是一个相当好用的特性,变量 i 的作用域仅限于 for 循环体内,不会与外部的变量 i 冲突,C语言的C99标准也支持这样的写法。但是,如果使用了C99之前的编译器,程序只能像下面这样写:
int i;
for (i = 0; i < n; ++i ) { ... }新增标准头文件
C99 增加了若干标准头文件,我觉得比较好用的有两个:
#include <stdio.h>
#include <stdbool.h>
int main() { bool a = true; bool b = false; bool c = 3;
printf("a,b,c = %d,%d,%d\n", a,b,c);
return 0;}
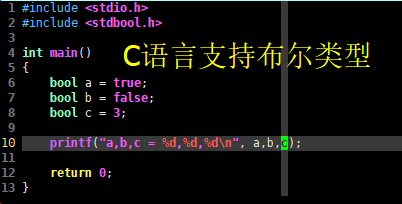 编译这段C语言代码并执行,得到如下输出,C语言的布尔类型被读出时,只有0,1两种可能值。
编译这段C语言代码并执行,得到如下输出,C语言的布尔类型被读出时,只有0,1两种可能值。
# gcc t.c
# ./a.out
a,b,c = 1,0,1“指定”赋值
在支持C99的编译器下,C语言程序员可以编写下面这样的代码,为特定的数组元素,或者特定的结构体成员赋值,请看下面这段C语言代码:
struct { int x, y; } a[10] = { [3] = { .y = 12, .x = 1 } };这段代码定义了数组 a,a 中元素存放的是一个有 x 和 y 两个成员的结构体,后面的赋值语句则指定为数组 a 的第 3 个元素赋值,并且指定 y 为 12,x 为 1。当然了,这段C语言代码仅作为示例,用于说明C99更加灵活的赋值特性。
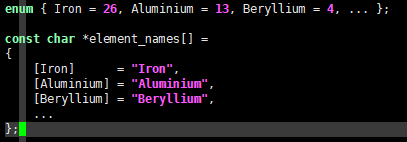
可见,C99允许C语言程序员随机初始化数组元素或者结构体成员,或许下面这个例子更能说明这一点,请看:
enum { Iron = 26, Aluminium = 13, Beryllium = 4, ... };
const char *element_names[] = { [Iron] = "Iron", [Aluminium] = "Aluminium", [Beryllium] = "Beryllium", ... };
“变长”数组
不少C语言教材在谈到数组时,往往都会强调定义数组必须使用“常量表达式”,而不能使用变量,例如下面这行C语言代码是违法的:
int len = 10;
int arr[len]; // C99之前违法在C99之前,如果需要申请一块由变量 len 指定长度的内存,只能借助动态内存分配。但是,C99标准允许使用“变量数组”,这大大方便了C语言程序开发,下面是一段合法的C语言代码示例:
int x;
scanf("%d", &x);
int a[x];
for (int i = 0; i < x; ++i)
a[i] = i * i;
for (int i = 0; i < x; ++i)
printf("%d\n", a[i]);显然,数组 a 的长度由变量 x 确定,这避免了动态内存分配,无需程序员再释放 a 了,减少了C语言程序的代码量,也降低了内存泄漏的风险。
这里应该指出,“变长数组”a依然存在于栈上。
小结
本节主要讨论了C99标准中新增的一些比较好用的“新特性”,应该明白,本文仅仅抛砖引玉,C99新增了相当多的好用特性,我之前的文章也有诸多讨论,为避免重复,这里就不再赘述了,感兴趣的读者可以再看看我之前的文章。