C语言陷阱与技巧第41节, 多次创建线程,内存消耗不断增加是怎么回事?线程退出也不释放内存
发表于: 2019-06-16 21:56:19 | 已被阅读: 1236 | 分类于: 杂谈
C语言程序是顺序执行的,所以一般来说,程序是按照程序员写的代码一行一行往下执行的。不过,C语言初学者可能会不知道这一点,写出输出不符合预期,又自己难以解释的代码。
例如前几天,群里有小伙伴问他的C语言程序为什么输出不符合预期,他的C语言代码是下面这样的:
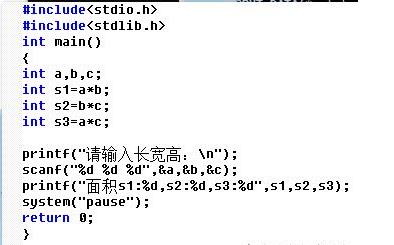
再来看小伙伴的C语言代码,显然是先计算了变量的乘积,然后才通过 scanf() 获取用户输入值,这肯定是不对的。
多线程编程
C语言初学者编写的C语言程序通常运行在一个线程里,此时第 n 条语句执行完毕之前,第 n+1 条语句一般不会有机会得到执行。这样的顺序执行程序处理简单任务还行,处理稍微复杂些的任务就有些力不从心了。
例如编写C语言程序处理大量数据,这样的工作一般相当耗时,要是程序仍然是单线程的,与用户交互时就可能出现“假死”(这在windows上表现为“未响应”,相信读者都遇到过),即使“假死”状态只持续几秒,对用户体验和系统流畅性也会造成恶劣的影响。
要避免程序出现交互“假死”,除了提升算法性能和机器运算能力,还可以使用多线程编程的技巧,也即让交互功能单独使用一个线程,其他阻塞时间较长的工作都放在其他线程处理。
在 Linux 系统下的C语言程序开发中,多线程编程是简单的,下面是一个例子,请看相关C语言代码:
#include <stdio.h>
#include <pthread.h>
void *data_process(void *p)
{
sleep(3);
printf("data process finished\n");
return NULL;
}
int main()
{
pthread_t pid;
pthread_create(&pid, NULL, data_process, NULL);
printf("hello world\n");
while(1);
return 0;
}
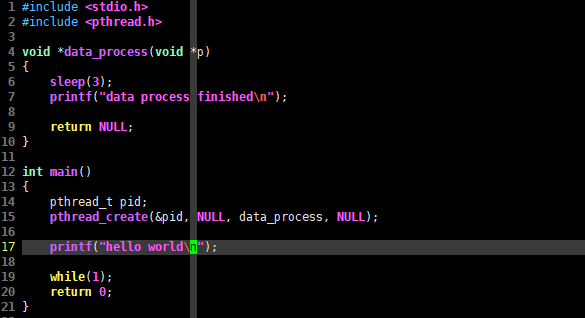
上述C语言代码没有做错误判断处理,因为这不是讨论主题。
假设 data_process() 是处理数据的函数,为了讨论主题,这里使用 sleep(3) 模拟处理耗时 3 秒。编译上述C语言程序并执行,得到如下输出:
# gcc t.c -lpthread
# ./a.out
hello world
data process finished
程序首先输出 “hello world”,3秒后输出“data process finished”,可见,耗时较久的 data_process() 并没有阻塞 main() 函数,如果交互程序由 main() 函数处理,显然交互程序不会进入“假死”状态。
多线程编程的“陷阱”
稍稍有些C语言编程经验的读者都不会觉得多线程编程难,但还是有可能跳进 pthread() 库的“陷阱”。现在我们对上述程序稍作修改,修改后的C语言代码如下,请看:
int main()
{
unsigned char i;
pthread_t pid;
for(i=0; i<10; i++)
pthread_create(&pid, NULL, data_process, NULL);
printf("hello world\n");
while(1);
return 0;
}
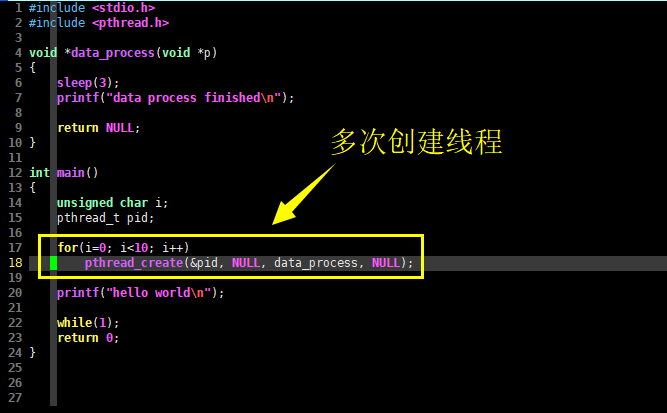

...
for(i=0; i<20; i++)
pthread_create(&pid, NULL, data_process, NULL);
...
编译修改后的C语言代码并执行,再次查看程序消耗的内存:

避免多线程编程的“陷阱”
应该明白,pthread_create() 创建的线程默认并不与主线程完全剥离,事实上,主线程会尝试获取子线程函数的返回状态。
在本例中,main() 函数会尝试获取 data_process() 的执行状态,而这里的 main() 函数并没有获取 data_process() 执行状态的C语言代码,系统自然不敢将 data_process() 完全释放,否则万一 main() 函数希望得到 data_process() 的返回状态就麻烦了。
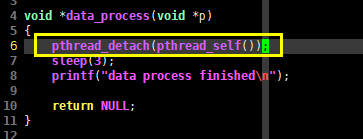
现在,我们可以将C语言中的线程分为两类:一类是主线程关心其返回状态的,一类是不被主线程关心的,如果某线程是后者,那系统就无需再保留其资源,线程执行完毕后,其内存自然会被释放。
void *data_process(void *p)
{
pthread_detach(pthread_self());
sleep(3);
printf("data process finished\n");
return NULL;
}


小结
本节先讨论了C语言程序的顺序执行特性,在此基础上讨论了阻塞过程可能会导致程序“假死”的情况,并且介绍了多线程编程,以解决该问题。本文重点讨论了Linux下C语言多线程编程时的“陷阱”,并较为详细的分析了原因,给出了解决该“陷阱”的一个方法。事实上,我们还可以在主线程中等待子线程返回,读者可自行尝试,如果觉得困惑,可以关注我,以后有机会会说的。