C语言陷阱与技巧第15节,错误处理太麻烦,不写行不行?
发表于: 2019-04-28 08:25:27 | 已被阅读: 915 | 分类于: C语言
在C语言程序开发中,调用一个有返回值的函数时,一般要对函数的返回值做判断,以确定函数是否按照预期执行。如果被调用函数没有按照预期执行,最好加上相应的错误处理代码,否则最终编译得到的C语言程序稳定性就不够好,遇到一点点意外,可能就不会正常工作了。
没有判断C语言函数的返回值,会有什么问题?
例如下面这段C语言程序:
char buf[128] = {0};
int fd = open("something", O_RDONLY);
read(fd, buf, sizeof(buf));
close(fd);
printf("%s", buf);
上面这段C语言程序首先定义了一个 buf 并且把它清零,程序员的本意是在 something 文件里存放一串字符串,并且通过 read() 函数将其读出,然后打印到控制台。
但是,可能因为某种原因,something 文件没有生成,那么上面这段C语言代码编译得到的程序就什么也不会输出了。遇到这种什么都没有输出的情况,初学者甚至可能会以为程序没有运行。
# gcc t.c
# ./a.out
#
要是这段C语言代码隐藏在一个比较大的项目间,something 文件是由其他逻辑生成的,这时要定位问题代码可能就要花些功夫了。
再看一个例子,相关C语言代码如下:
char *buf = (char *)malloc(128);
sprintf(buf, "date is %s", date());
printf("%s", buf);
free(buf);
可以看出,程序员的本意是申请一块内存,并且让 buf 指向它,然后在 buf 中存放一段字符串并输出到控制台。然而,这段代码隐藏着一个比较严重的隐患——

C语言程序中的“段错误”出现时,通常不会有其他错误提示信息,这对于调试来说是比较难受的。不过在 Linux 中可以设置 core dumped,利用 gdb 等工具排查。不管如何,“段错误”都是相对来说比较难定位的错误。
所以,在编写C语言程序时,判断函数的返回值非常重要。通过返回值,我们能够知道函数有没有正常运行,如果它没有正常运行,就做相应的错误处理,只有这样,最终得到的C语言程序才能应对各种意外。
加上函数返回值判断
现在将上面两段 C语言代码改写——增加返回值判断逻辑:
char *buf = (char *)malloc(128);
if(NULL==buf){
printf("malloc failed, %m\n");
}else{
int fd = open("something", O_RDONLY);
if(fd < 0){
printf("open file failed, %m\n");
free(buf);
}else{
if(-1==read(fd, buf, sizeof(buf))){
printf("read file failed, %m\n");
close(fd);
free(buf);
}else{
printf("%s", buf);
free(buf);
close(fd);
}
}
}
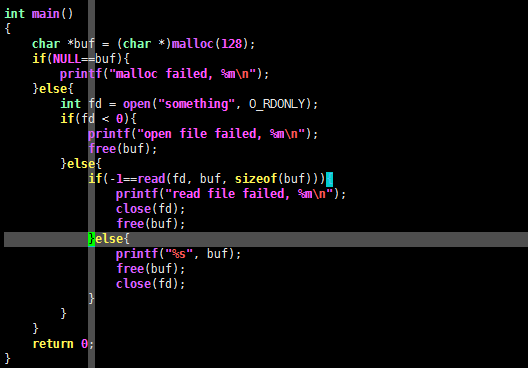
printf("errno: %d, %s\n", errno, strerror(errno));
但是更方便的做法是借助 printf() 函数提供的 “%m”,以下两行C语言代码是等价的:
printf("%m");
// 等价于
printf("%s", strerror(errno));
现在编译上面的C语言代码并且执行,得到如下输出:
# gcc t.c
# ./a.out
open file failed, No such file or directory
这样一来,就算C语言程序遇到“意外情况”,程序也不会反应都没有。从这段输出我们可以知道:open() 函数执行失败了,原因是“No such file or directory(没有这样的文件或者目录)”。对于本例而言,这是因为当前目录没有 something 文件。
去掉啰嗦的语句
请看下面的C语言代码:
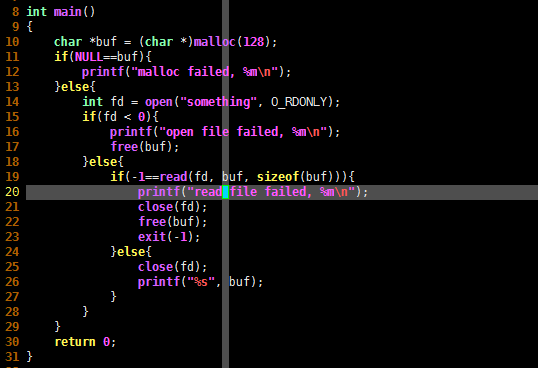
之前的文章介绍过使用 do{}while(0) 将若干代码封装成宏的技巧,其实 do{}while(0) 的作用还不止于此,请看下面的C语言代码:
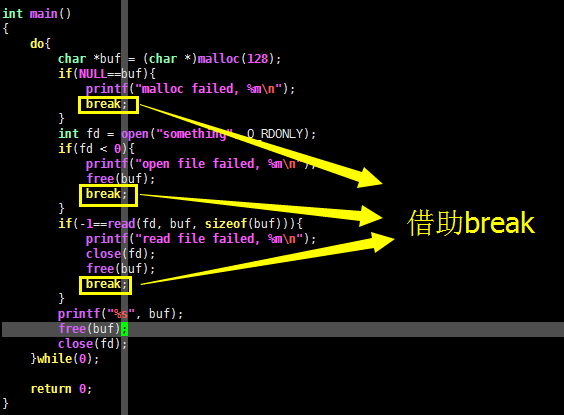
int main()
{
do{
char *buf = (char *)malloc(128);
if(NULL==buf){
printf("malloc failed, %m\n");
break;
}
int fd = open("something", O_RDONLY);
if(fd < 0){
printf("open file failed, %m\n");
free(buf);
break;
}
if(-1==read(fd, buf, sizeof(buf))){
printf("read file failed, %m\n");
close(fd);
free(buf);
break;
}
printf("%s", buf);
close(fd);
free(buf);
}while(0);
return 0;
}
那该怎么办呢?
虽然很多人不提倡使用 goto 语句,但是它确实能够很方便的处理错误,请看下面的C语言代码:
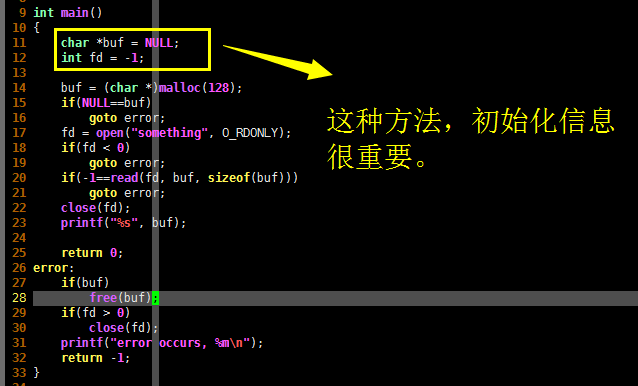
想想为什么?
小结
本节介绍了C语言程序开发过程中,判断函数返回值的重要性。并且介绍了两种处理错误逻辑的“技巧”,读者可自行比较这几种风格代码,欢迎在评论区分享您的观点。