Linux学习第28节,自旋锁的C语言代码实现
发表于: 2019-03-09 21:50:06 | 已被阅读: 976 | 分类于: Linux笔记
上一节主要介绍了 Linux内核中的原子操作,在某种程度上避免了多个线程对同一全局变量的竞争问题。要是内核中的其他C语言程序开发中的临界区都能像上一节介绍的原子变量那样简单就好了。

自旋锁简介
Linux 内核开发中,最常使用的锁是自旋锁。如果线程 A 获得了自旋锁,其他线程再请求锁的时候就无法获得,必须等待线程 A 释放自旋锁。也就是说,一个自旋锁同时只能被一个线程持有,用其保护共享资源就太合适了。
若线程 B 请求一个已经被线程 A 持有的自旋锁,则线程 B 会一直执行类似 while(1); 的自旋动作,直到线程 A 释放自旋锁。能够看出,自旋等待非常耗费处理器,因此任何线程都不应该长时间持有自旋锁。
Linux 内核还有其他类型锁的设计,它会让线程 B 睡眠,直到线程 A 释放自旋锁的时候才重新唤醒线程 B。这样处理器就不必白白把时间花在等待上,而是可以在此期间执行其他代码。那为什么还要设计自旋锁呢?

自旋锁的C语言代码实现
使用自旋锁是简单的,基本操作就是初始化锁、请求锁、释放锁,用C语言代码描述这一过程就是:
DEFINE_SPINLOCK(lock);
spin_lock(&lock);
/* 临界区 */
spin_unlock(&lock);
从上述C语言代码可以看出,在使用自旋锁之前,应先初始化,DEFINE_SPINLOCK() 是一个宏,它的C语言代码如下:
#define DEFINE_SPINLOCK(x) spinlock_t x = __SPIN_LOCK_UNLOCKED(x)
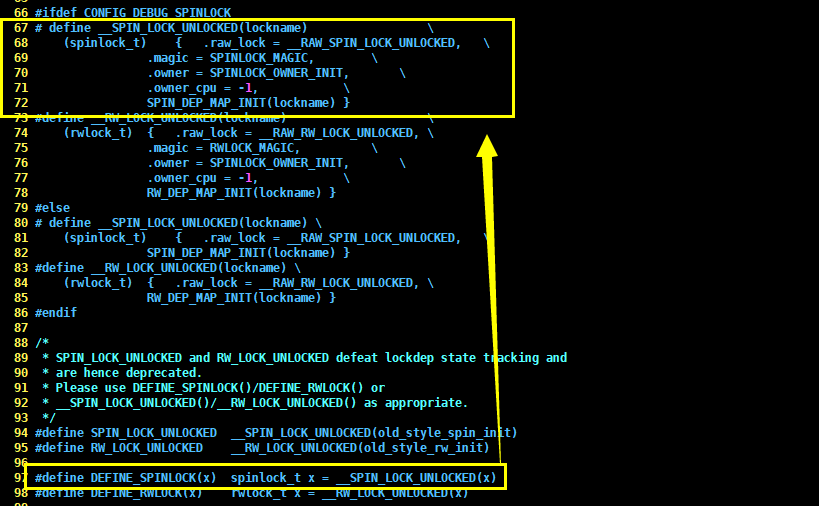
20 typedef struct {
| 21 raw_spinlock_t raw_lock;
| 22 #ifdef CONFIG_GENERIC_LOCKBREAK
| 23 unsigned int break_lock;
| 24 #endif
| 25 #ifdef CONFIG_DEBUG_SPINLOCK
| 26 unsigned int magic, owner_cpu;
| 27 void *owner;
| 28 #endif
| 29 #ifdef CONFIG_DEBUG_LOCK_ALLOC
| 30 struct lockdep_map dep_map;
| 31 #endif
| 32 } spinlock_t;
自旋锁初始化后,在进入需要保护的临界区之前,应先调用 spin_lock() 请求自旋锁。spin_lock() 也是一个宏,它的C语言代码如下,请看:
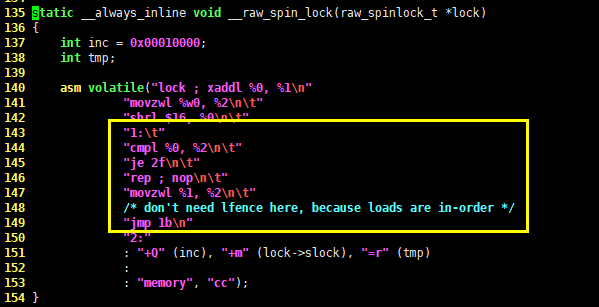
#define spin_lock(lock) _spin_lock(lock)
继续跟踪
135 static __always_inline void __raw_spin_lock(raw_spinlock_t *lock)
- 136 {
| 137 int inc = 0x00010000;
| 138 int tmp;
| 139
| 140 asm volatile("lock ; xaddl %0, %1\n"
| 141 "movzwl %w0, %2\n\t"
| 142 "shrl $16, %0\n\t"
| 143 "1:\t"
| 144 "cmpl %0, %2\n\t"
| 145 "je 2f\n\t"
| 146 "rep ; nop\n\t"
| 147 "movzwl %1, %2\n\t"
| 148 /* don't need lfence here, because loads are in-order */
| 149 "jmp 1b\n"
| 150 "2:"
| 151 : "+Q" (inc), "+m" (lock->slock), "=r" (tmp)
| 152 :
| 153 : "memory", "cc");
| 154 }
退出临界区后,应调用 spin_unlock() 释放自旋锁。与上面的过程类似,跟踪相关C语言代码,会发现 spin_unlock() 也是因平台而异的,在x86 平台下,它的核心功能由
static __always_inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
asm volatile(UNLOCK_LOCK_PREFIX "incb %0"
: "+m" (lock->slock)
:
: "memory", "cc");
}
其他自旋锁操作
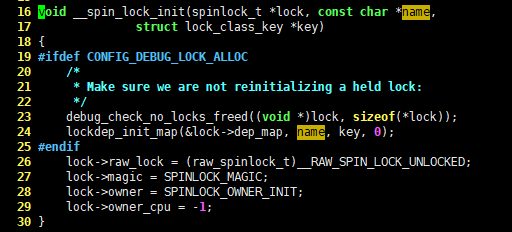
上面主要介绍了自旋锁的三大基本功能。当然,我们还可以调用 spin_lock_init() 初始化动态创建的锁,spin_lock_init() 接收一个 spinlock_t 类型的指针作为参数,它的核心功能由
16 void __spin_lock_init(spinlock_t *lock, const char *name,
17 struct lock_class_key *key)
- 18 {
| 19 #ifdef CONFIG_DEBUG_LOCK_ALLOC
| 20 /*
| 21 * Make sure we are not reinitializing a held lock:
| 22 */
| 23 debug_check_no_locks_freed((void *)lock, sizeof(*lock));
| 24 lockdep_init_map(&lock->dep_map, name, key, 0);
| 25 #endif
| 26 lock->raw_lock = (raw_spinlock_t)__RAW_SPIN_LOCK_UNLOCKED;
| 27 lock->magic = SPINLOCK_MAGIC;
| 28 lock->owner = SPINLOCK_OWNER_INIT;
| 29 lock->owner_cpu = -1;
| 30 }
spin_lock() 函数在请求已被别的线程持有的锁的时候,会阻塞等待。如果希望请求已被持有的锁时,程序不阻塞,而是返回一些标识值区分是否成功,则可以使用 spin_try_lock()。如果请求的自旋锁已经被别的线程持有,则 spin_try_lock() 会立刻返回一个非 0 值,否则就是成功获得该自旋锁,返回 0。此外,还有 spin_is_locked() 方法可以检查特定的锁当前是否被占用,占用返回非 0,否则返回 0.
再写一点
使用锁的时候,应该明白我们需要保护的是数据而不是代码。常说的要保护临界区,其实就是指临界区内的数据,而不是代码。如果由这样的思路,加锁时就不会迷茫了,只要保证访问共享数据前加锁,访问完毕解锁即可。
我们之前提到, 中断处理程序运行在中断上下文中,因此不可以睡眠,所以不能使用允许睡眠的锁机制。这种情况下,不会睡眠的自旋锁就是保护共享数据的首选了。
