linux多cpu编程,为线程指定cpu,sched_setaffinity和sched_getaffinity的详解与使用,使用time命令得到程序执行时间
发表于: 2018-10-11 15:59:56 | 已被阅读: 1789 | 分类于: C语言
查看 linux 主机的 cpu 信息
在linux主机下执行
$ lscpu | grep -i 'core.*:|socket'
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
意思是我的linux主机有 1 个 cpu,每个 cpu 的核心有 2 个,每个核心支持 2 个线程。那么在进行多线程编程的时候,如何为某个线程指定 cpu(
sched_setaffinity 函数简介
首先
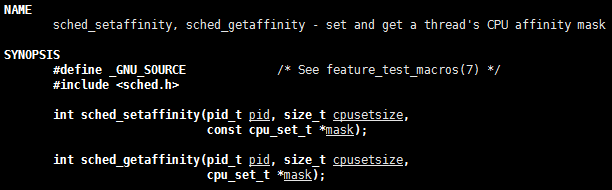
如果函数调用成功,返回 0,失败的话,返回 -1,错误码放入
这个函数可以决定线程在指定的 cpu 中运行。在多进程系统中,适当的为线程指定 cpu 可以提升效率,比如,指定线程 A 在 cpu 0 中运行,限定其他线程在其他 cpu 运行,那么线程 A 的执行速度和实时性就可以得到最大程度的保障。另外,cpu 也是有高速缓存的,执行线程频繁切换 cpu 也会导致缓存的命中率大大降低,同样影响执行效率。
By the way,
为线程指定 cpu,CPU_SET 系列宏的介绍和使用
继续
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <sched.h>
打开该头文件
vim /usr/include/sched.h
发现宏定义的底层定义在
vim /usr/include/bits/sched.h
得到
# define __CPU_SETSIZE 1024
# define __NCPUBITS (8 * sizeof (__cpu_mask))
typedef unsigned long int __cpu_mask;
# define __CPUELT(cpu) ((cpu) / __NCPUBITS)
# define __CPUMASK(cpu) ((__cpu_mask) 1 << ((cpu) % __NCPUBITS))
typedef struct
{
__cpu_mask __bits[__CPU_SETSIZE / __NCPUBITS];
} cpu_set_t;
# define __CPU_ZERO(cpusetp) \
do { \
unsigned int __i; \
cpu_set_t *__arr = (cpusetp); \
for (__i = 0; __i < sizeof (cpu_set_t) / sizeof (__cpu_mask); ++__i) \
__arr->__bits[__i] = 0; \
} while (0)
# define __CPU_SET(cpu, cpusetp) \
((cpusetp)->__bits[__CPUELT (cpu)] |= __CPUMASK (cpu))
# define __CPU_CLR(cpu, cpusetp) \
((cpusetp)->__bits[__CPUELT (cpu)] &= ~__CPUMASK (cpu))
# define __CPU_ISSET(cpu, cpusetp) \
(((cpusetp)->__bits[__CPUELT (cpu)] & __CPUMASK (cpu)) != 0)
其实就是定义了一个
使用 sched_setaffinity 函数 demo
下面这个程序创建一个子进程,父子进程都为自己指定一个 cpu,然后都循环执行一段代码消耗一些 cpu 运行时间。程序运行时需要3个参数,分别是: 即将为父进程指定的 cpu 号,即将为子进程指定的 cpu 号,循环执行代码的循环次数。
#define _GNU_SOURCE
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE); \
} while (0)
int main(int argc, char *argv[])
{
cpu_set_t set;
int parentCPU, childCPU;
int nloops, j;
if (argc != 4) {
fprintf(stderr, "Usage: %s parent-cpu child-cpu num-loops\n",
argv[0]);
exit(EXIT_FAILURE);
}
parentCPU = atoi(argv[1]);
childCPU = atoi(argv[2]);
nloops = atoi(argv[3]);
CPU_ZERO(&set);
switch (fork()) {
case -1: /* Error */
errExit("fork");
case 0: /* Child */
CPU_SET(childCPU, &set);
if (sched_setaffinity(getpid(), sizeof(set), &set) == -1)
errExit("sched_setaffinity");
for (j = 0; j < nloops; j++)
getppid();
exit(EXIT_SUCCESS);
default: /* Parent */
CPU_SET(parentCPU, &set);
if (sched_setaffinity(getpid(), sizeof(set), &set) == -1)
errExit("sched_setaffinity");
for (j = 0; j < nloops; j++)
getppid();
wait(NULL); /* Wait for child to terminate */
exit(EXIT_SUCCESS);
}
}
编译之,然后我们使用 linux 的
- 父子进程使用同一个 cpu
- 父子进程使用同一个核心的不同 cpu
- 父子进程使用不同的核心不同的 cpu
测试结果如下:
$ time -p ./a.out 0 0 100000000
real 14.75
user 3.02
sys 11.73
$ time -p ./a.out 0 1 100000000
real 11.52
user 3.98
sys 19.06
$ time -p ./a.out 0 3 100000000
real 7.89
user 3.29
sys 12.07
real time 是指实际消耗的时间,user time 是指程序运行在用户态消耗的时间,sys time 是指程序运行在内核态消耗的时间,在父子进程使用同一个 cpu 时,real time 近似等于 user time 与 sys time 之和。当为父子进程指定不同的 cpu 时,real time 小于 user time 与 sys time 之和了,这是因为 user time 和 sys time 统计的是总时间,这里父子进程共使用了两个 cpu,因此总的消耗时间被分摊了,此时可以看出 real time 近似等于 user time 与 sys time 之和的一半。