Ubuntu 16.04 从 GitHub下载 caffe 源码,并且编译安装,Caffe 的依赖库都有什么作用?
发表于: 2019-11-22 09:16:00 | 已被阅读: 933 | 分类于: Caffe
最近几年,得益于计算机计算能力的飞速提升,互联网的高速发展和应用产生海量的数据,依赖计算能力和大数据的深度学习发展迅速,以人脸识别、语音识别为代表的人工智能行业非常火热,几乎每一家科技公司都会提出 AI 的概念。
深度学习发展的相当迅速,以至于这个行业的人才紧缺,根据近几年的行业薪水统计,人工智能相关的人才薪资总体遥遥领先于其他行业,可见一斑。
再先进的科技总归要落地于企业级的应用才会真的火热,早期若要将深度学习算法应用到实践中,少不了编写程序,遗憾的是,精通算法的人才不一定也精通编程,一套优秀的算法可能会因为水平稍次的程序效率大打折扣,这也不利于研究人员集中精力研究算法,也不利于人们交流彼此的算法(没有统一的标准)。
为此,各种深度学习框架逐步出现。本文不打算讨论各种深度学习框架的特点和区别,鉴于我接触的很多项目都需要 Caffe 支持,所以。。。
若要学习 Caffe,首要任务当然是安装它。下面将在 Ubuntu 16.04 X86_64 系统中安装 Caffe。
Caffe 的安装
首先需要安装一批 caffe 的依赖库,这些依赖库一般都可以通过 apt 命令安装,依次输入以下命令:
$ sudo apt update
$ sudo apt install git
$ sudo apt install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
$ sudo apt install --no-install-recommends libboost-all-dev
$ sudo apt install libatlas-base-dev
$ sudo apt install python-dev
$ sudo apt install libgflags-dev libgoogle-glog-dev liblmdb-dev
安装完依赖库后,使用 git 命令从 GitHub 下载 Caffe 源代码后:
$ git clone https://github.com/bvlc/caffe.git
在编译之前,需要配置 makefile,这个配置项可以直接在官方提供的模版基础上修改:
$ cp Makefile.config.example Makefile.config
$ vim Makefile.config
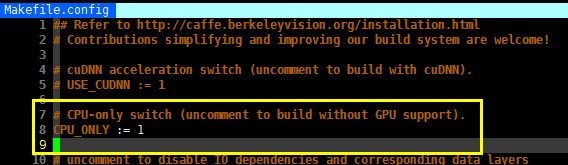
如果所使用机器没有 GPU,则可以编译只有 CPU 版本的,方法就是修改 Makefile.config 中的 CPU_ONLY 选项,将其解注释(删除前面的'#')。输入以下命令即可编译:
$ make -j
-j 选项可以自动使用所有可利用 CPU 编译。也可以在其后手动指定使用的 CPU 个数。
编译 Caffe 可能会遇到的问题
在编译过程中,我遇到了下面这样的错误:
fatal error: hdf5.h: No such file or directory compilation terminated
这是因为 Makefile 找不到 hdf5.h 头文件,可是依赖库明明已经通过 apt 命令安装了,所以这里需要手动指定。打开 Makefile.config 文件,搜索 INCLUDE_DIRS,在其后添加我们安装的 hdf5 头文件所在目录,我的是 /usr/include/hdf5/serial:

然后再打开 Makefile,搜索LIBRARIES,对两个依赖库添加后缀_serial(这是由前面安装的 hdf5 决定的):

再次输入 make 命令,发现上述问题解决了。但是又遇到了下面这样的错误:
.build_release/lib/libcaffe.so: undefined reference to cv::imread(cv::String const&, int)
这是因为我前面通过 apt 命令安装的 OpenCV 是 3.3.1 版本的,所以需要在 Makefile.config 中指定使用的是 OpenCV 3:
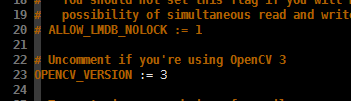
再次输入 make 命令,发现 Caffe 编译完成了。
Caffe 的依赖库
在编译 Caffe 之前,安装了不少依赖库,这些依赖库都是干什么用的呢?
Snappy
Caffe 主要使用 Snappy 处理一些压缩和解压缩工作,Snappy 比 Zlib 快,但是压缩率没有 Zlib 高,文件相对要大 20%~100%。
LMDB 和 LEVELDB
这两个库可以非常快速的将原始数据(raw图片,或者raw二进制数据)以 Key-Value 的形式快速映射到内存,在 Caffe 中起到数据管理的作用。
HDF5
HDF5 是一种能够高效存储和分发的新型数据格式,能够在不同类型的机器上传输并且解析,Caffe 主要使用它存储不同类型的图像和数码数据的文件。
ProtoBuffer
ProtoBuffer 是 Google 开发的一种可以实现内存与非易失存储介质(如硬盘)交换的协议接口,Caffe 大量使用了该协议接口作为权值和模型参数的载体。
所谓的“协议”,其实就是为了统一标准。因为 Caffe 会产生大量的参数权值,如何存储和使用它的方法五花八门,而每个人都有自己的使用习惯,有人喜欢 txt 文件的易修改,有人喜欢 bin 文件的高效读写。
如果不能统一标准,就会对开发组的协作产生阻碍,因此 ProtoBuffer 就被使用了,它甚至还能跨语言(C++/Java/Python)传递相同的数据结构,让开发组的协作更有效率。
输入以下命令:
$ vim models/bvlc_reference_caffenet/train_val.prototxt
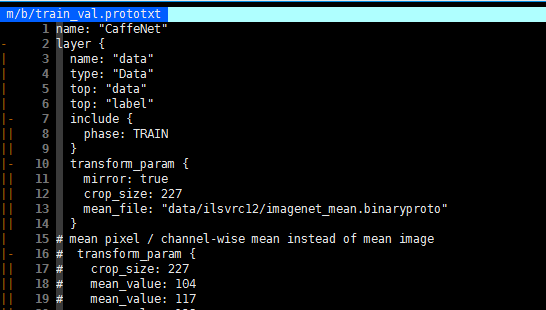
该文件记录了模型训练所需的一些参数,使用 Caffe 训练时会首先读取该文件。而将数据从该磁盘文件读取到内存的过程就是有 ProtoBuffer 完成的。
#include "caffe.pb.h"
#include "google/protobuf/io/coded_stream.h"
#include "google/protobuf/io/zero_copy_stream_impl.h"
#include "google/protobuf/text_format.h"
caffe::SolverParameter param;
int fd = open(filename, O_RDONLY);
google::protobuf::io::FileInputStream *input =
new google::protobuf::io::FileInputStream(fd);
google::protobuf::TextFormat::Parse(input, ¶m);
只需要上述几行简单的代码,就可以将 filename 中的内容解析到 param 中。例如,输出 device_id 的代码可以这样写:
cout<<"Device id: "<<param.device_id()<<endl;
关于 Caffe 中的 ProtoBuffer 的更多细节,可以参考 caffe.proto 中的 SolverParameter 协议、caffe.pb.h、caffe.pb.cc。
GLOG
GLOG 是 Google 开发的用于记录程序日志的库,能够设置不同的日志级别,便于区分查看。开发者通过日志可以查看 Caffe 训练过程中的输出并依此调参控制收敛,还可以通过它定位问题,跟踪源码等。
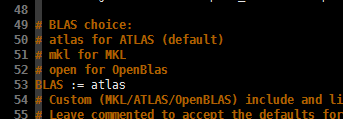
BLAS
Caffe 中有大量的矩阵和向量运算,这一过程使用了 BLAS 中的相应方法,比较常用的有 Intel MKL,ATLAS,OpenBLAS 等。打开编译时的配置文件 Makefile.config,即可看到相应的设置: