C语言如何定义“可变参数”函数?计算机是如何处理可变参数函数的?
发表于: 2019-10-25 08:36:19 | 已被阅读: 1143 | 分类于: C语言
如果一定要说哪段C语言代码最“著名”,我想非“hello world”莫属了。大多数初学者人生中编写的第一段C语言代码就是这段“里程碑”式的代码:
#include <stdio.h>
int main() { printf("hello world\n"); return 0; }
 头文件
头文件<stdarg.h>声明了 va_list 类型用于描述可变参数,并且定义了上述 4 个方法解析。这里不打算介绍过多枯燥的理论知识,我们直接看实例,请看相关C语言代码:
#include <stdio.h>
#include <stdarg.h>
void foo(char *fmt, ...) { va_list ap; int d; char c, *s;
va_start(ap, fmt);
while (*fmt)
switch (*fmt++) {
case 's': /* string */
s = va_arg(ap, char *);
printf("string %s\n", s);
break;
case 'd': /* int */
d = va_arg(ap, int);
printf("int %d\n", d);
break;
case 'c': /* char */
/* need a cast here since va_arg only
takes fully promoted types */
c = (char) va_arg(ap, int);
printf("char %c\n", c);
break;
}
va_end(ap);}
int main() { foo("%s, %d, %c\n", "hello", 12, 'm');
return 0;}
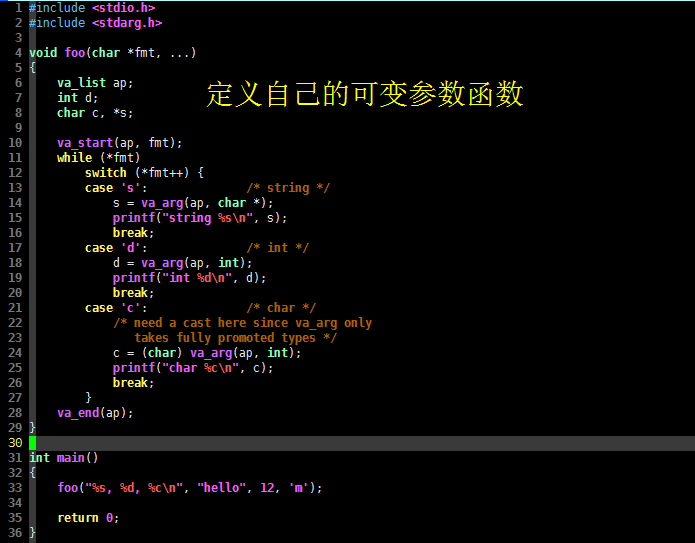 上述代码定义了可变参数函数 foo(),它可以接收类似于 printf() 的函数,并且将 fmt 中的 s 解析为字符串,d 解析为整数,c 解析为字符,因此编译并执行这段C语言代码,可得到如下输出:
上述代码定义了可变参数函数 foo(),它可以接收类似于 printf() 的函数,并且将 fmt 中的 s 解析为字符串,d 解析为整数,c 解析为字符,因此编译并执行这段C语言代码,可得到如下输出:
# gcc t.c
# ./a.out
string hello
int 12
char m通过这段实例,可以看出使用C语言定义可变参数函数并不复杂,在处理可变参数时,只需先调用 va_start() 将参数序列加载到 va_list 结构的变量中,然后调用 va_arg() 依次解析。解析完毕后,再调用 va_end() 结束解析。
va_start -> va_arg -> va_end。
唯一需要注意的是使用 va_arg() 解析参数时,需要指定类型。但是这个过程也很简单,可变参数函数的实现者可以指定一套规则,用于约束函数调用者传递参数,这样就知道接下来需要解析的参数是何种类型。例如上面的C语言代码就约定了 fmt 中的 s 表示接下来的要解析的参数是字符串,d 表示整数等。
计算机是如何处理可变参数函数的?
C语言定义可变参数函数的过程并不复杂,借助于<stdarg.h>,我们能够轻易的定义接收任意多参数的函数,不过到这里,有读者发现问题了:我们人类可以按照规则写出可变参数函数,但是计算机是如何理解这一套规则的呢?或者换句话说,计算机是如何处理“可变参数”的?
以Linux为例,看过我之前文章的读者应该明白,每个C语言程序进程都有属于自己的栈,进程中的每个函数则有属于自己的栈帧,当有函数调用时,例如:
foo("%d%d%d", 3,2,1);C语言编译器会产生类似于下面这样的汇编代码:
push 1
push 2
push 3
push "%d%d%d"
call foo也即将 foo() 函数的参数先压入栈中,然后再调用 foo() 函数。鉴于栈这种数据结构“先进后出”的特点,一般函数参数的入栈顺序是从右至左的。
[] // 空栈
-------------------------------
push 1: [1]
-------------------------------
push 2: [1]
[2]
-------------------------------
push 3: [1]
[2]
[3] // 参数 1 2 3 被压入栈中
-------------------------------
push "%d%d%d":[1]
[2]
[3]
["%d%d%d"]
-------------------------------
call foo ... // foo 函数开始使用参数 按照这样的参数入栈顺序,foo() 函数使用参数很方便,依次从栈中将参数取出就可以了。至于如何解析栈中的参数,则可以根据可变参数实现者指定的规则,例如在格式化字符串 fmt 中遇到 s 就解析为字符串等。
按照这样的参数入栈顺序,foo() 函数使用参数很方便,依次从栈中将参数取出就可以了。至于如何解析栈中的参数,则可以根据可变参数实现者指定的规则,例如在格式化字符串 fmt 中遇到 s 就解析为字符串等。
如果可变参数 foo() 接收到其他数目的参数,对于最终程序来说,也仅仅只需要修改压栈的参数数目,其他并无太多不同。
小结
本文主要讨论了C语言中可变参数函数的定义方法,以及计算机如何处理可变参数函数的过程,其实并不复杂。C语言不像C++那样支持函数重载,但是借助于可变参数函数和宏,我们可以像定义“伪类”那样,定义自己的“伪函数重载”,这是一种编程技巧,以后有机会再讨论了。