C语言面试题详解第15节
发表于: 2019-03-22 16:50:43 | 已被阅读: 707 | 分类于: C语言
上一节介绍了算法的概念,讨论了算法与程序开销,以及程序工作效率之间的关系,并且在最后给出了一道面试题,要求使用C语言写出几种常用的数组排序算法,并比较各种方法的工作效率。限于篇幅,上一节主要讨论了

冒泡排序法
提到数组排序,就不得不说一下
请用 C 语言写出一个冒泡排序程序,要求输入10个整数,输出排序结果。
将数组 list 中的每个元素看作是密度为 list[i] 且互不相溶的液体,按照物理学定律,密度小的液体总是会上浮到密度大的液体之上,这一过程看起来就像是气泡从水底漂浮到水表面一样,因此参考照顾原理实现的数组排序法称为

if(list[j]>list[j+1]){
tmp = list[j];
list[j] = list[j+1];
list[j+1] = tmp;
}
将上述过程应用到整个数组,就能实现一次完整的冒泡排序了,相关C语言代码如下,请看:
void bubbling_sort(int *list, int len)
{
int i, j , tmp;
for(i=0; i<len-1; i++){
for(j=0; j<len-1-i; j++){
if(list[j]>list[j+1]){
tmp = list[j];
list[j] = list[j+1];
list[j+1] = tmp;
}
}// for(j=0; j<len...
}
}

# gcc t.c
# ./a.out
0 1 2 3 4 5 6 7 8 9
冒泡排序可以纳入交换排序,基本思想都是两两比较待排序的数组元素,若发现元素次序相反就立即交换之,直到没有数组中反序排列的元素为止。
快速排序法
基于交换排序思想的另一个典型排序方法是
快速排序法不再比较数组的相邻元素了,而是从数组中找出一个元素值作为
int list[10] = {4, 2, 1, 5, 9, 6, 3, 8, 0, 7};

- 移动 j,找出小于 4 的数值并记录其位置,显然是 0(list[8]);
- 移动 i,找出大于 4 的数值并记录其位置,显然为 5(list[3]);
- 交换 list[3] 和 list[8] 的数值,此时 list 的数值为 {4, 2, 1, 0, 9, 6, 3, 8, 5, 7}。

{4, 2, 1, 0, 3, 6, 9, 8, 5, 7}

{3, 2, 1, 0, 4, 6, 9, 8, 5, 7}
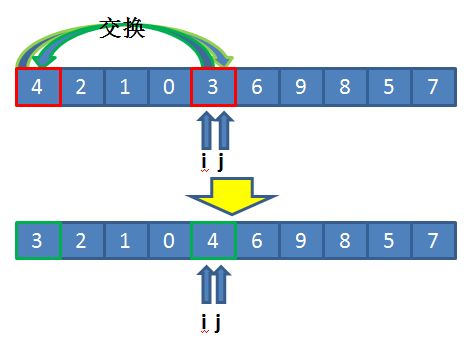
{3, 2, 1, 0}
{6, 9, 8, 5, 7}
不过,只要对左右两个子数组再进行一次上述操作,一直到整个数组排序完毕就可以了。显然,利用递归非常容易解决这类问题。
关于递归,前面两节已较为详细的讨论,感到陌生的朋友可以翻回去看看。
现在知道了
下面这段C语言代码是实现快速排序的函数,补全最后的代码。
void improveqsort(int *list, int m, int n)
{
int k,t,i,j;
if(m<n){
i = m;
j = n+1;
k = list[m];
while(i<j){
for(i=i+1; i<n; i++)
if(list[i]>=k)
break;
for(j=j-1; j>m; j--)
if(list[j]<=k)
break;
if(i<j){
t = list[i];
list[i] = list[j];
list[j] = t;
}
}
t = list[m];
list[m] = list[j];
list[j] = t;
improveqsort( , , ); /* 补全参数 */
improveqsort( , , ); /* 补全参数 */
}
}

显然,improveqsort() 函数是一个递归函数。观察 improveqsort() 函数的参数,推测它应该可以完成数组 list 第 m 个到第 n 个元素的排序。
下面为了分析方便,以上图中的行号为准。
第 7 行的 if(m<n) 限定了 improveqsort() 函数只对长度大于 1 的数组排序,若输入的数组长度小于 1,则函数就直接退出了,这其实就是前面两节中提到的“递归函数退出条件”。

对照前文的分析,执行完第 26 行代码后,数组 list[m~n] 中小于 list[m] 的数值全部被移到 list[m] 左边,大于 list[m] 的数值则全部被移到 list[m] 右边了。此时需要对左右两个“子数组”进一步做快速排序,因此面试题的代码给出了两次 improveqsort() 函数的调用。那么传递给它们的参数应该是什么呢?
improveqsort(list, i, n);
improveqsort(list, m, j-1);
并且两句代码不分前后。现在在 main() 函数中调用补全后的 improveqsort() 测试:
int main()
{
int list[10] = {9, 4, 2, 1, 5, 6, 3, 8, 0, 7};
int i;
improveqsort(list, 0, 9);
for(i=0; i<10; i++)
printf("%d ", list[i]);
printf("\n");
return 0;
}
编译上述C语言代码并执行,发现输出与预期一致:
# gcc t.c
# ./a.out
0 1 2 3 4 5 6 7 8 9
其实,快速排序法是基于一种叫做“二分”的思想,类似的还有
小结
利用C语言解决问题的方法常常不止一种,这两节介绍的几种数组排序法就是一个例子。为什么要像孔乙己那样研究“茴”字有几种写法呢?这是因为计算机的运算速度并不是无限快,存储空间也不是无限大。冒泡排序法的确非常简单,但是它的执行效率却比较低,只适合处理较短的数组排序。

- 平方阶排序:一般称为简单排序,典型例子有插入排序、冒泡排序;
- 线性对数阶排序:如快速排序,归并排序;
- 幂阶排序:如希尔排序;
- 线性阶排序:如桶、箱等以空间换时间的排序法。
应明白,不能简单认为某种排序算法一定比其他排序法好,可能在数学上某种算法的确很具效率,但是在实际中还要考虑计算机的实际运算速度以及存储空间,很有时间效率的算法可能是牺牲了大量存储空间换来的。应在不同条件下,选用不同的排序法,例如:
- 若数组长度很短(如小于50),可采用插入排序法
- 若数组基本有序,可采取冒泡排序
- 若数组较长,选择快速排序或者归并排序则比较合适