C语言没有类似于 Java 的“垃圾回收”等高级编程语言特性,也不像 python 那样无需显示声明类型就能使用变量,因此在很多人看来,C语言有些“低级”。但是C语言的这些“低级”也是 C语言的优点——使用C语言开发程序,程序员能够准确知道究竟使用了多少资源,以及哪些资源还在内存里,哪些已经被释放。换句话说,C语言程序具备资源的使用确定性。
因此,C语言特别适合用于一些资源比较匮乏的项目开发中。在这些项目中,以嵌入式项目为代表,一般都需要严格控制内存的使用——使用 1 个字节(Byte)就能存放的值,绝对不定义 2 个字节宽度的变量。甚至,一些“抠门”的C语言程序员会将 1 个字节掰成若干个位(bit)使用。
所以,在C语言程序开发中,常常需要操作某个变量特定的位(bit),这对于C语言来说当然没有任何难度,各种移位操作就能够方便的解决该类需求,例如:
unsigned char status;
status |= 0x01 << 2;
status &= ~0x01;
上面第二行C语言代码将 status 的第3个位(bit 2)设置为 1,第三行C语言代码将 status 的第1个位(bit 0)设置为 0。可以看出,借助于位运算,C语言可以比较简单的操作 status 的指定位。不过,C语言这种操作位的方法有时候看起来不够直观——至少没有直接赋值那么直观。
那C语言有没有更加直观的位操作方法呢?
上面的例子通过移位、以及或与非等操作实现对变量 status 的位操作,但是看起来却不是那么直观,那么C语言有没有更加直观的位操作方法呢?似乎可以借助C语言的联合体(union)和位域(bit field)语法,间接的实现位操作,请看下面的C语言代码:
union convert{
unsigned char status;
struct __bits {
unsigned char bit0:1;
unsigned char bit1:1;
unsigned char bit2:1;
unsigned char bit3:1;
unsigned char bit4:1;
unsigned char bit5:1;
unsigned char bit6:1;
unsigned char bit7:1;
}v;
};
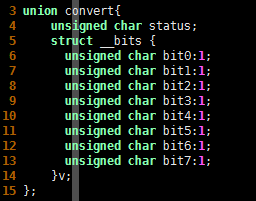
此例中 status 和 bits 结构体共享一个字节的内存空间,结构体 bits 利用C言中的位域语法将一个字节的内存空间拆分成 8 个位,这种情况下,要读写 status 的位就非常简单了,请看下面的C语言示例代码:
union convert cv;
// 写 status 的 bit 3
cv.v.bit3 = 0;
// 写 status 的 bit 7
cv.v.bit7 = 1;
// 读 status 的 bit 5
r = cv.v.bit5;
编写 main() 函数,测试通过位域操作 status 的位,相关C语言代码如下,请看:
int main()
{
union convert cv;
cv.status = 0;
cv.v.bit3 = 1;
cv.v.bit1 = 1;
printf("%d\n", cv.status);
return 0;
}
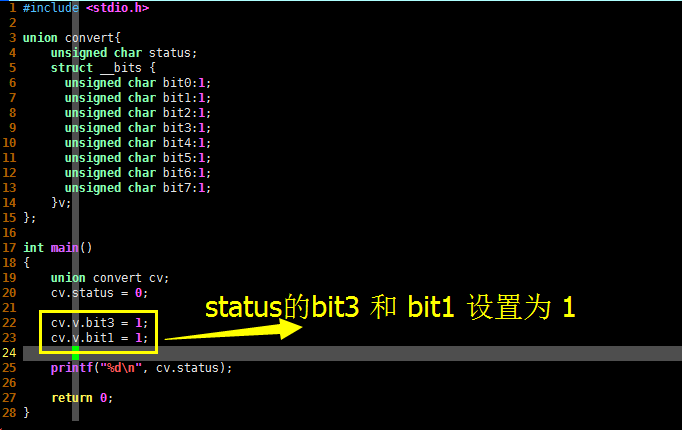
main() 函数一开始将 status 置为 0,然后将它的 bit1 和 bit3 设置为 1,也就相当于将 status 设置为 0x0a,编译并执行这段C语言代码,得到如下输出:
# gcc t.c
# ./a.out
10
一切与预期一致,这样就实现了以“赋值”的形式,操作C语言中的位,而且看起来比“移位与或非操作”更加直观,所以这样的操作更好了?
事实上,有一些C语言程序员的确这么用,至少我的一些同事喜欢这样的位操作。
警惕“常识陷阱”
1 个字节(Byte)等于 8 个位(bit)似乎已经是程序员间的常识了,很少有人质疑这一点。但是作为C语言程序员,我们常常要在不同的硬件平台上做底层开发,应该明白:1个字节等于8个位只是惯例而已,C标准并没有定义这一点。有些编译器并不遵守这个惯例,例如,在 Texas 的 C55x DSP 的平台上,1 个字节等于 16 个位。在这个平台上,各种数据类型占用的位数有些奇怪:
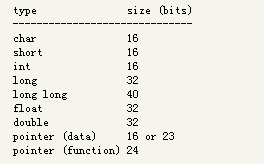
以 long long 为例,在该平台上 long long 之所以等于 40 bit,而不是我们常用的 64 bit,是因为它们的 ALU 是 40 bit 宽,因此编译器规定 long long 为 40 bit 可以降低功耗和提升效率。
另外, 就算在 1 个字节等于 8 个位的硬件平台上,单个字节的 8 个位是如何分布的也是没有明确标准的。

