C语言陷阱与技巧第2节,inline函数介绍,demo详解
发表于: 2019-04-28 08:16:56 | 已被阅读: 933 | 分类于: C语言
打开 Linux 内核源代码,会发现内核在定义C语言函数时,有很多都带有 “inline”关键字,请看下图,那么这个关键字有什么作用呢?

inline 关键字的作用
在C语言程序开发中,inline 一般用于定义函数,inline 函数也被称作“内联函数”,C99 和 GNU C 均支持内联函数。那么在C语言中,内联函数和普通函数有什么不同呢?其实,从 inline 这个名字就应该能看出一点它的性质了——
将被调用的函数代码展开,操作系统就无需再在为被调用函数做申请栈帧和回收栈帧的工作,而且,由于编译器会把被调用的函数代码和函数本身放在一起优化,所以也有进一步优化C语言代码,提升效率的可能。
每发生一次函数调用,操作系统就要在程序的栈空间申请一块内存区域(栈帧),供被调用函数使用,被调用函数执行完毕后,操作系统还要回收这些内存。

显然,如果滥用内联函数,cpu 的指令缓存肯定是不够用的,这会导致 cpu 缓存命中率降低,反而可能会降低整个C语言程序的效率。因此,建议把那些对时间要求比较高,且C语言代码长度比较短的函数定义为内联函数。如果在C语言程序开发中的某个函数比较大,又会被反复调用,并且没有特别的时间限制,是不适合把它做成内联函数的。
在 Linux 内核中,内联函数常常使用 static 修饰,例如:
static inline void set_value(unsigned int val)
{
...
}
需要注意的是,内联函数必须在使用之前就定义好,否则编译器没法把这个函数展开。Linux 内核中经常像下面这样,将内联函数放在调用它的函数前面,请看C语言代码:
static inline void set_value(unsigned int val)
{
...
}
int test_inline()
{
set_value(3);
...
}

这也解释了为什么 Linux 内核为何常常使用 static 修饰内联函数,因为可以避免函数的重复定义。
前文提到内联函数的表现有些像 define 宏定义,但是为了类型安全和易读性,应优先使用内联函数而不是复杂的宏。下面通过实例进一步分析 inline 内联函数的特性。
inline内联函数的“展开代码”是什么意思?
使用过 define 写 C语言代码的朋友应该都知道,编译器在编译 C语言代码时,会将 define 定义的宏展开,而不是像普通函数那样使用 call 指令调用,例如下面这段C语言代码:
#include <stdio.h>
#define d_add(a, b) ((a)+(b))
int f_add(int a, int b)
{
return a+b;
}
int main()
{
int a = d_add(1, 2);
int b = f_add(1, 2);
return 0;
}


# gcc -g t1.c
# objdump -dS a.out

static inline int i_add(int a, int b)
{
return a+b;
}


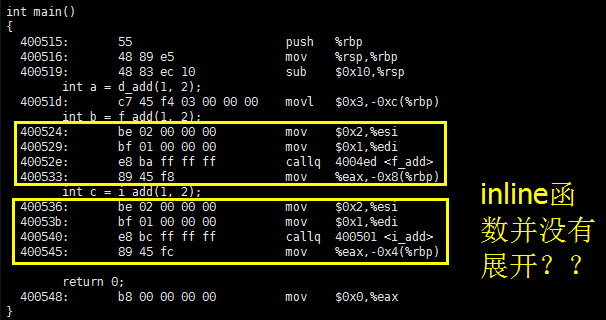
static inline int i_add(int a, int b)
{
400501: 55 push %rbp
400502: 48 89 e5 mov %rsp,%rbp
400505: 89 7d fc mov %edi,-0x4(%rbp)
400508: 89 75 f8 mov %esi,-0x8(%rbp)
return a+b;
40050b: 8b 45 f8 mov -0x8(%rbp),%eax
40050e: 8b 55 fc mov -0x4(%rbp),%edx
400511: 01 d0 add %edx,%eax
}
400513: 5d pop %rbp
400514: c3 retq
怎么回事?不是说 inline 函数的表现和 define 宏相似,会将函数代码展开吗?其实,inline 只是

static __attribute__((always_inline)) inline int i_add(int a, int b)
{
return a+b;
}


inline 函数虽然表现上很像 define 宏定义,但是却并不能完全取代 define 宏定义,这一点在我之后的文章里会讨论,敬请关注。
小结
在 C语言程序开发中,建议把那些对时间要求比较高,且C语言代码长度比较短的函数定义为 inline 函数,这么做常常可以提升程序的效率。在默认的 -O0 编译优化项不能确保 inline 一定起作用,但是可以添加添加
