C语言面试题详解(第3节),基础要是不牢,就很容易中套
发表于: 2019-02-05 20:30:23 | 已被阅读: 748 | 分类于: C语言
研究看似“奇葩”的面试题目,很能帮助我们查漏补缺,找到自身知识的不足,巩固自己的技术基础。

先来看看这个问题
请看下面这个C语言程序,它来自中国台湾某著名 CPU 生产公司的面试题,一起思考下,这道题会输出什么呢?
#include <stdio.h>
int main()
{
unsigned char a = 0xa5;
unsigned char b = ~a>>4+1;
printf("b=%d\n", b);
return 0;
}

A. 245 B. 246 C. 250 D. 2
估计大部分人都会选 D,[/斜眼笑]。
初步分析
大致分析下,发现这个问题似乎考察两个知识点:一是类型转换问题,再就是运算符的优先级问题。先来分析
unsigned char b = ~a>>4+1;
因为程序没有指定数值 4 和 1 的类型,所以编译器会将其默认为 int 类型。~ 的优先级高于 >>,+ 的优先级高于 >>,所以上面这句 C 语言代码相当于下面这句:
unsigned char b = (~a)>>5;

也就是先对 a 取反,再右移 5 位。0xa5 取反之后就是 0x5a,再右移 5 位,得到 0x2。那看起来应该选 D 了?验证答案最简单的方法就是写好代码,编译执行:
# gcc t.c
# ./a.out
b=250
怎么回事?并不是预计的 2,b 居然等于 250!这是为什么呢?
进一步分析
相信大家应该都知道,在C语言程序计算的过程中,如果运算符两边的数值类型不一致,编译器会做一些隐式的自动转换。这种数据类型转换比较复杂,但是总体遵循这个准则:
这就明白了,若是需要隐式的转换数据类型,编译器总是尽量的往较宽数据类型(占用内存空间较多,比如 int 类型常常比 char 类型宽)转换。例如,如果某次计算中,计算数的类型是 long double,那么另一个操作数无论是什么类型,都会被转换位 long double 类型,因为 C 语言中没有比 long double 还宽的数据类型了。

如果计算过程中的计算数不是浮点数,那么它们肯定都是整型,编译器一般会将所有小于 int 类型宽度的数据类型转换位 int 类型,这其实就是所谓的“整值提升”。
知道了“整值提升”的概念,再来考虑上面的思考题就简单了。a 是 unsigned char 类型的数据,小于 int 类型的宽度,因此在 a 进行取反运算之前,会现将其提升到 int 类型宽度。
C标准并没有定义 int 类型的宽度,在我的机器上,int 类型占用 4 个字节的内存空间,因此将 a 转换位 int 类型后,a 等于 0x000000a5,取反后就等于 0xffffff5a 了,然后再右移 5 位,得到 0x07fffffa。现在将其赋值给 b,而 b 是 unsigned char 类型的,

那怎样才能得到 D 答案呢?现在已经明白最终 b 等于 250 是因为 C语言编译器做了“整值提升”,我们强制其不做该转换就可以了,所以可以如下修改 C 语言代码:
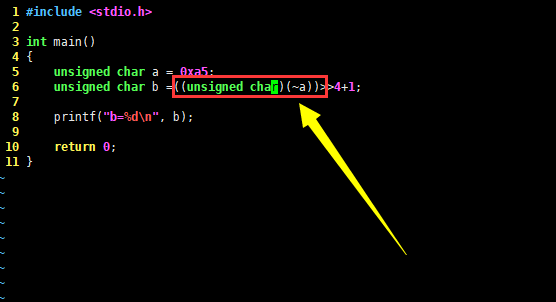
#include <stdio.h>
int main()
{
unsigned char a = 0xa5;
unsigned char b = ((unsigned char)(~a))>>4+1;
printf("b=%d\n", b);
return 0;
}
# gcc t.c
# ./a.out
b=2
总结
至此,我们就解决了这道面试题。可以看出,此题有陷阱,若是对C语言的隐式数据类型转换不熟悉,就很容易上套,得出错误的答案。隐式数据类型转换虽然比较复杂,但是可以说,一切都是基于这条准则: