c语言入门26,宏定义的使用
发表于: 2018-11-27 20:35:59 | 已被阅读: 881 | 分类于: C语言
前面几节较详细的介绍了 C 语言指针的用法,尤其在上一节,我们讨论了如何利用 C 语言实现“伪类”。有朋友评论说这样没有意义,的确,在上一节的例子中的确没有什么意义,伪类”甚至还让本来简单的代码变得更繁杂了。但是,在

事实上,linux 内核源代码中有大量使用“伪类”的地方,本节不再讨论“伪类”。
谈到
函数式宏定义
像 #define N 20 这种宏定义称为“变量式”宏定义,N 可以像变量一样使用,但是 N 属于常量表达式。实际上,还有一种可以像函数一样使用的宏定义,可称之为“函数式宏定义”,请看如下代码:
#define MIN(a, b) ( (a)<(b)?:(a):(b) )
x = MIN(3&0x0f, 5&0x0f)
将 x = MIN(3&0x0f, 5&0x0f) 表达式展开,得:
x = ( (3&0x0f)<(5&0x0f)?(3&0x0f):(5&0x0f) )
d = a?b:c 这个表达式的意思是,if(a) d=b; else d=c;

可以看出,函数式宏定义 MIN 可以像函数一样使用,两个实参被替换到宏定义形参 a 和 b 的位置了。应当注意,函数式宏定义和真正的函数是有区别的:
- 函数式宏定义的参数没有类型,预处理时不做参数类型检查,所以使用时要确保类型正确。
- 函数式宏定义本身不会被编译为函数,调用时就是直接把宏定义替换过来,而不是简单的几条传参和 call 指令,所以函数式宏定义编译生成的目标会比真正的函数大。
- 定义函数式宏定义要非常小心,如果 MIN 定义成 #define MIN(a, b) ( a<b? a:b ),则 x = MIN(3&0x0f, 5&0x0f) 展开就成了 x = ( 3&0x0f<5&0x0f?3&0x0f:5&0x0f ),运算符的优先级就错了,不会得出正确结果。读者思考一下,外层括号能否省略?
- 因为调用函数式宏定义就是简单替换,所以如果 MIN(i++, j++) 时,展开就是 ( (i++)<(j++)?(i++):(j++) ),i和j自加的次数是不确定的。如果是 MIN 真正的函数,则 i 和 j 确定是只自加一次。

在 linux 内核中,函数式宏定义通常使用 do{...}while(0) 包裹:
#define do_something(i) \
do{ \
i ++; \
printf("i = %d\n", i); \
}while(0)
为什么呢?请看下面这个例子,就明白了:
if(i>5)
do_something(i);
else
printf("test\n");
如果没有使用 do{...}while(0) 包裹,把 do_something 展开后,变为:
if(i>5)
i++;
printf("i = %d\n", i);
else
printf("test\n");
printf("i = %d\n", i); 这句没有被包含在 if 判断语句里,而且 else 语句并没有与 if 配对,所以编译会报错。那能否在宏定义时,使用 {} 包裹呢?还是上面的例子,使用 {} 包裹展开后:
if(i>5)
{
i++;
printf("i = %d\n", i);
}; // ;
else
printf("test\n");
虽然 printf("i = %d\n", i); 这句被包含在 if 判断语句里了,但是 do_something(i); 最后的 “;”会被展开到 {} 后面,这样表示 if 的判断结束了,else 依然没有与 if 配对,还是会编译报错。那 do_something(i); 后面的这个“;”不写不就行了吗?的确,不写就没有错误了,但是不写 ";",看起来就不像函数调用了,对不?整个语句显得怪怪的,哪天顺手一加,就又错了。

C 语言宏定义的 ## 运算符
请看实例:
#define test(a, b) a##b
test(he, llo)
test(he, llo) 预处理后,就相当于 hello。再请看:
#include <stdio.h>
#define test(a) print##a
void print1()
{
printf("hello 1\n");
}
void print2()
{
printf("hello 2\n");
}
int main()
{
test(1)();
test(2)();
return 0;
}
显然,“##”是一个特殊的拼接符,说它特殊是

利用 define 也可以实现一些不定参数的函数式宏定义,请看:
// 开发时
#define debug(format, ...) printf(format, ## __VA_ARGS__)
// 发行时
#define debug(format, ...)
这么定义以后,debug 就可以像 printf 一样使用了。在开发阶段,需要打印出信息时,使用 debug 代替 printf。这么做的好处是,开发完毕不再需要打印信息时,只需要简单的把 debug 定义为空即可,而无需再去挨个删除 printf。以后还想打印信息,再把 printf 添加回来即可。
有时候,函数式宏定义可以做到函数难以实现的事
现在的 C 语言及其编译器支持了很多有趣的关键字,例如:
__FUNCTION__ 表示函数名
__LINE__ 表示所在行号
等等
请看如下代码:
#include <stdio.h>
int main()
{
printf("%s %d\n", __FUNCTION__, __LINE__);
return 0;
}
编译器在编译时,会自动的把 "

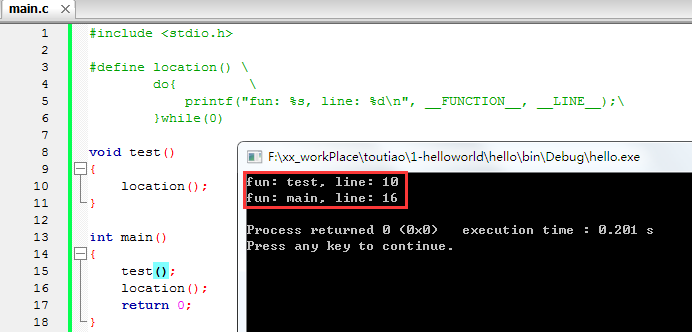
#include <stdio.h>
#define location() \
do{ \
printf("fun: %s, line: %d\n", __FUNCTION__, __LINE__);\
}while(0)
void test()
{
location();
}
int main()
{
test();
location();
return 0;
}
打印出位置是有用的,它能帮助我们在大型项目的复杂代码中快速的找到出错的函数,出错的行号。(类似于
在 windows 环境中开发,各种 IDE 把程序员照顾的很好。但是有些错误,即使是 IDE 也无法定位,以后会看到这样的例子。另外,嵌入式开发中,可不一定有合适的 IDE 给程序员使用。
location 是一个函数式宏定义,所以调用它,就相当于把代码展开到调用位置,所以它可以打印出 test 中的位置,也可以打印出 main 中的位置。如果 location 是一个真正的函数,输出结果就不同了,请看:
