linux下的C开发8,I/O函数简介,读写普通文件
发表于: 2019-01-06 13:42:47 | 已被阅读: 378 | 分类于: Linux笔记
通过前面几节的介绍,相信朋友们都能搭建自己的 linux 开发环境了。
接下来,小编决定介绍一下 linux 中 C语言程序开发中常用的一些函数,并在这一实践过程中进一步了解 linux 内核。这样不至于使学习过程太过枯燥,也能顺便积累一些开发经验。

在整理这些函数的过程中,小编发现即使是经常使用的函数,也有一些值得回味的东西。
I/O 函数的缓冲
先来说说 linux 中 C语言程序开发常用的 I/O 函数。大多数程序员常常将 I/O 函数分为“带缓冲”的和“不带缓冲”的两类。
这里说的“缓冲”其实是指用户空间的一块内存区域。一般来说,“带缓冲”的 I/O 函数写数据时,并不直接写磁盘介质,而是将数据先写到这块内存缓冲中,之后用户空间缓冲中的数据会被传送到系统缓冲中(fflush函数可以加速这一过程),稍后 linux 内核会将系统缓冲中的数据送完磁盘驱动器(fsync函数可以加速这一过程),这之后,数据才真正的被写入磁盘。
设计缓冲的原因,主要是因为目前内存的读写速度(常 ns 级)往往远大于硬盘的读写速度(常 ms 级)。因此,缓冲区的建立可以尽力避免太过频繁的写磁盘。而且对于硬盘来说,写入一个字节可能跟写入一个扇区没什么两样,程序员每次写入的数据也许就几个字节,所以可以将每次写入的几个字节放入缓冲区,排列组合成一整块数据再写入,也能极大的提升效率。

“带缓冲”的 I/O 读函数读取数据之前,则会首先判断用户空间的进程缓冲区是否包含数据,如果没有,则继续判断系统缓冲区是否包含数据,如果缓冲区有数据,就直接从内存缓冲区中取数据,避免了较慢的读磁盘操作。
一般来说,“带缓冲”的 I/O 读函数从磁盘读取数据时,并不只读取调用者指定的读取字节数。例如,程序员调用读函数从磁盘读取 10 字节数据,读函数可能一次性读取一个扇区(常常是 512B)保存在缓冲区里,只返回给程序员需要的 10 字节。这么设计,主要是因为相信该程序员使用了这里的 10 字节数据,那么他接着使用接下来的数据可能性是非常大的,因此一次性多读取点放在内存里。
归根结底,缓冲区的设计就是为了减少耗时较多的读写 I/O 操作。
“不带缓冲的”I/O 函数
本节讨论的是“不带缓冲的”I/O 函数族,“带缓冲的”函数以后再讨论。最常用的“不带缓冲”的 I/O 函数族,包含 open、read、write、lseek 以及 close 五个函数。
其实,按照上面的讨论,“不带缓冲”这个说法并不准确。read、write 函数还是有系统缓冲区的。
Unix 认为“一切皆文件”,无论是磁盘,还是设备,甚至一段内存,都可以当作是文件来操作。linux 作为类 unix 系统,自然也是如此。一般来说,在 C语言中,操作文件的基本流程是:
打开文件 -> 读写文件 -> 关闭文件
使用 open 函数即可打开文件,按照上一节介绍的,在linux 中输入 man 命令即可查询到 open 函数的使用说明:
# man 2 open

从文档中,即可看到 open 函数所需要的头文件,它的函数原型,以及各个参数的意义和返回值等信息。其他几个函数也可以通过 man 命令查询。下面给出一段 C语言读写文件的代码示例,请看:
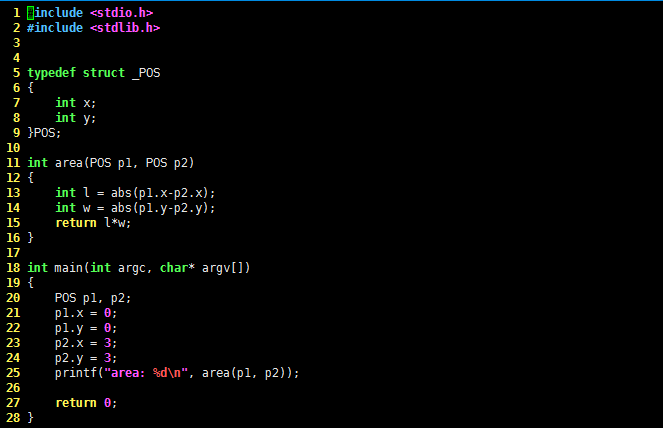
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
char rbuf[128] = {0};
int fd = open("test.txt", O_RDWR|O_CREAT);
write(fd, "hello embedTime", strlen("hello embedTime"));
close(fd);
fd = open("test.txt", O_RDWR|O_CREAT);
read(fd, rbuf, sizeof(rbuf));
close(fd);
printf("read data: %s\n", rbuf);
return 0;
}
# gcc t.c
# ./a.out
read data: hello embedTime
C语言中的 lseek 函数
上面给出的示例,我们写入数据后,为了读出它,又重新打开了一次文件,这不是啰嗦了吗?直接下面这样写行吗?
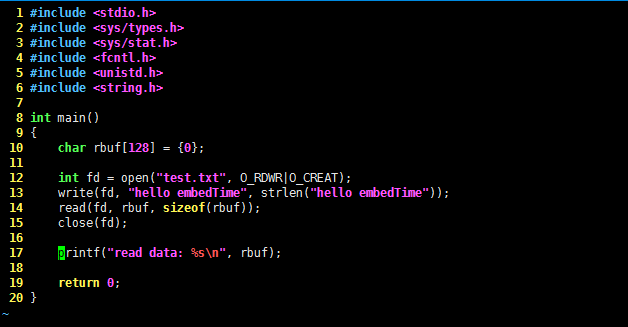
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
char rbuf[128] = {0};
int fd = open("test.txt", O_RDWR|O_CREAT);
write(fd, "hello embedTime", strlen("hello embedTime"));
read(fd, rbuf, sizeof(rbuf));
close(fd);
printf("read data: %s\n", rbuf);
return 0;
}
# gcc t.c
# ./a.out
read data:
怎么回事,读出来的数据是空的。这其实是因为系统记录 I/O 函数每次读写的位置指针,无论是 write 函数,还是 read 函数都会改变这一读写指针的位置。这就明白了,当 write 函数写入“hello embedTime”后,读写指针就被移到 “embedTime”的最后了,read 函数读取时,也是从这里开始读的,后面没有数据了,读出来的自然就是空了。
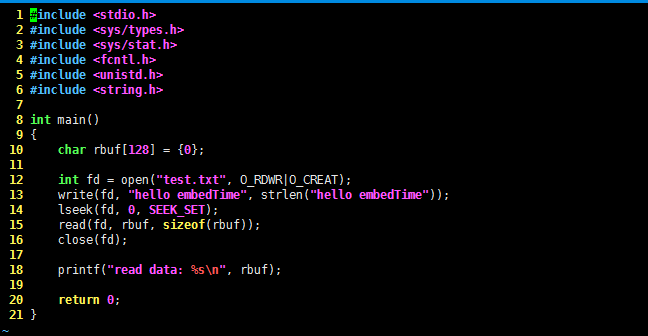
所以,如果想读出数据,只需要把读写文件的位置指针移到文件最前面,就行了。lseek 函数正可以完成这项工作,可以使用 man 命令查看它的手册,下面直接给出修改后的代码了,请看:
...
write(fd, "hello embedTime", strlen("hello embedTime"));
lseek(fd, 0, SEEK_SET);
read(fd, rbuf, sizeof(rbuf));
...
# gcc t.c
# ./a.out
read data: hello embedTime