linux下的C开发12,复制一个文件描述符,dup和dup2函数介绍
发表于: 2019-01-06 13:55:04 | 已被阅读: 1286 | 分类于: Linux笔记
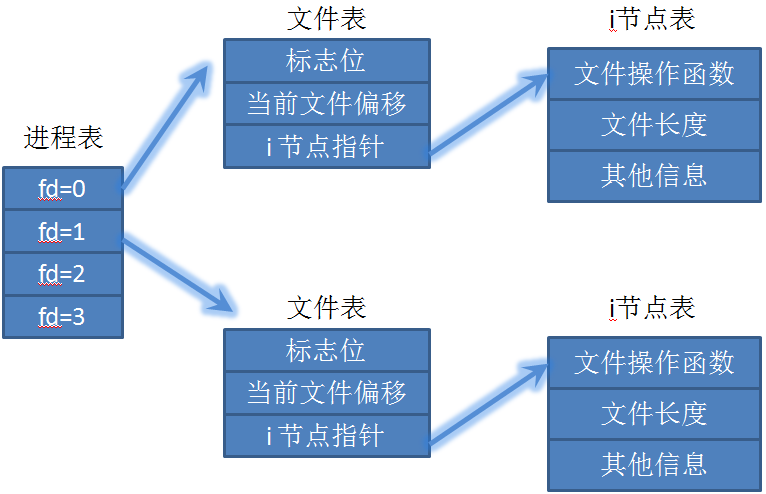
经过上一节的介绍,我们知道在 linux 中进行 C语言开发时,多进程同时写数据到同一个文件,如果不小心处理,写入的数据可能会混乱。这主要是因为每个进程打开文件时,都有独立的文件表记录当前文件偏移量的原因。

请看下面的代码:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
char* filename = "test.bin";
int fd, fd2;
fd = open(filename, O_WRONLY|O_CREAT);
fd2 = open(filename, O_WRONLY|O_CREAT);
char buf1[20] ;
char buf2[30] ;
memset(buf1, 1, sizeof(buf1));
memset(buf2, 2, sizeof(buf2));
write(fd, buf1, sizeof(buf1));
write(fd2, buf2, sizeof(buf2));
close(fd);
close(fd2);
return 0;
}
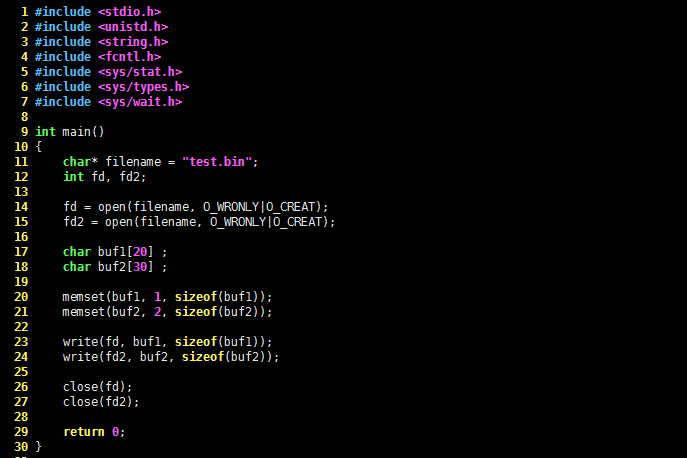
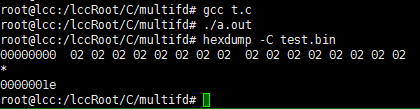
实际开发中,还是非常有可能需要打开同一个文件多次的,比如多线程项目中,每个线程都需要操作 test.bin 文件,这时使用多个 fd 更加方便。
C语言的 dup 和 dup2 函数
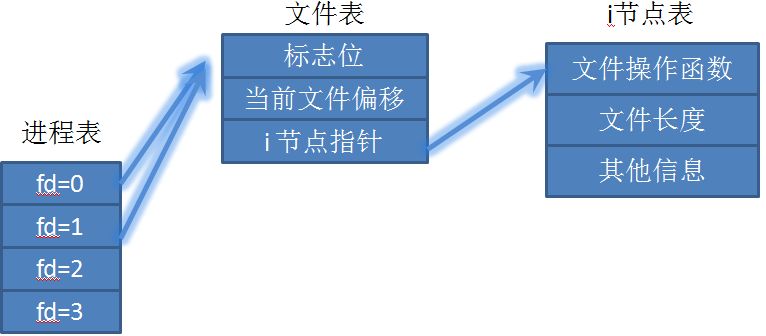
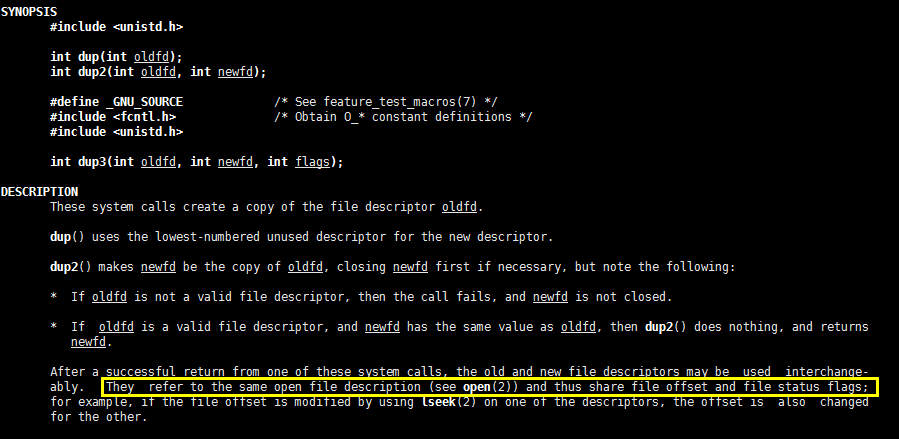
好在,C语言提供的 dup 和 dup2 函数,就非常适合解决多个 fd 写数据到同一个文件的需求。dup 和 dup2 都可用来复制一个现存的文件描述符,使两个文件描述符指向同一个文件表。
...
fd = open(filename, O_WRONLY|O_CREAT);
fd2 = dup(fd);
char buf1[20] ;
...
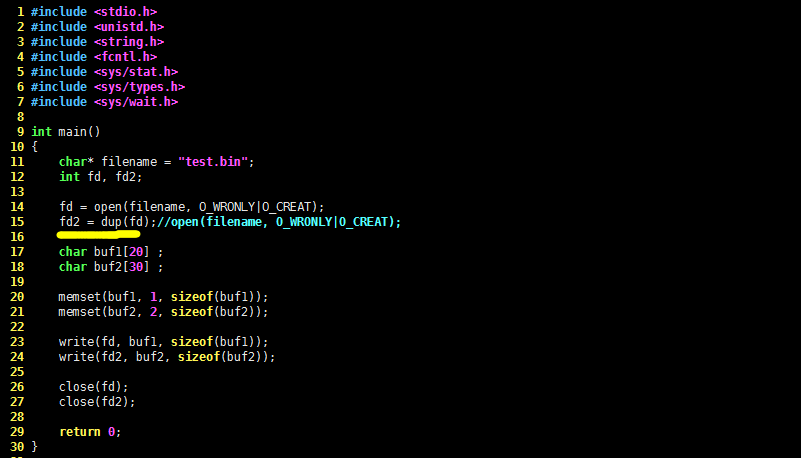
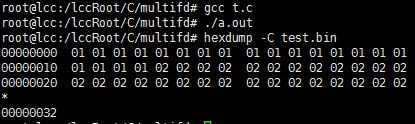
再看看上面的代码,虽然 fd2 是复制 fd 而来的,但是仍需调用 close 函数关闭之。所以如果只执行第 26 行代码,linux 内核只会将 test.bin 文件的打开计数减一,并没有真正关闭文件。因此,第 27 行的 close(fd2); 是必需的。
这也能看出多线程操作同一个文件,使用 dup 的好处了。某个线程使用完文件后,直接 close 即可(这能使代码有更好的逻辑完整性,可阅读性更强),而无需担心其他线程。
dup 函数复制 fd 时,总是返回尽可能小的未使用 fd 号。dup2 函数与 dup 函数的功能时类似的,唯一的区别是 dup2 函数有两个参数,执行成功后,会返回第二个参数传递的 fd 值。

多进程打开同一个文件时,能利用 dup 函数避免数据紊乱吗?
既然 dup 函数能够复制 fd,那么,上一节出现的问题也能用 dup 函数的特性解决吗?这个问题就留给读者思考了。经过这两节的讨论,相信读者也有能力编写相应的 C语言代码验证自己的想法。
这里有一点小提示:进程间通常并不共享内存,而进程打开文件时,文件表信息保留在自己的内存空间里的。