linux学习13,进程调度
发表于: 2019-01-06 13:58:08 | 已被阅读: 971 | 分类于: Linux笔记
前面两节介绍了一下 linux 中进程的资源,本节再来学习下 linux 中进程的调度。
linux 进程的时间记账

上一节说到为了尽量让每个进程都有相对公平的机会运行,linux 在设计进程调度时,提出了 cpu使用比的概念,那么 linux 是如何统计每个进程的 cpu 使用比的呢?这就需要对每个进程进行时间记账了。
事实上,不仅是 linux,几乎所有调度器都需要对进程的运行时间记账。多数类 unix 系统都会分配给进程一个时间片,每当系统的时钟节拍增加时,进程的时间片就相应的减少一个节拍周期,进程的时间片减小到 0 就会被别的进程抢占。
虽然上一节说到 linux 的 cfs 调度法不再使用时间片(使用cpu使用比),但是它也仍然需要记录每一个进程的运行时间,因为 cfs 需要知道每个进程的运行状态,才能做出相对公平的调度。cfs 用于记录时间的结构体如下:
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 last_wakeup;
u64 avg_overlap;
...
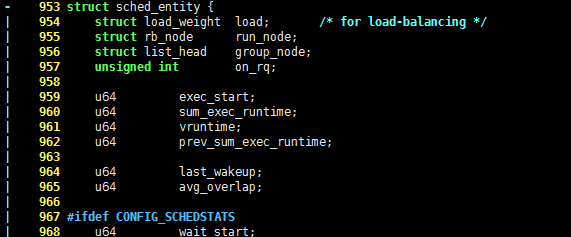
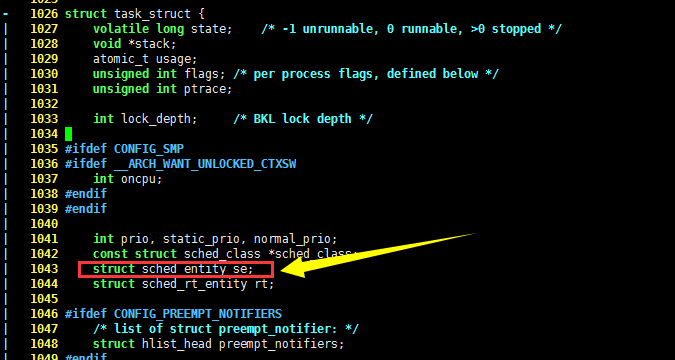
知道了每个进程的运行时间,要计算它的 cpu 使用比,还需要所有进程的运行时间总和,linux 内核是使用 vruntime 记录这一数值的,它的单位是 ns。为了让 vruntime 不与定时器相关,vruntime 实际上是所有进程运行时间经过加权处理的。
linux 的记账函数
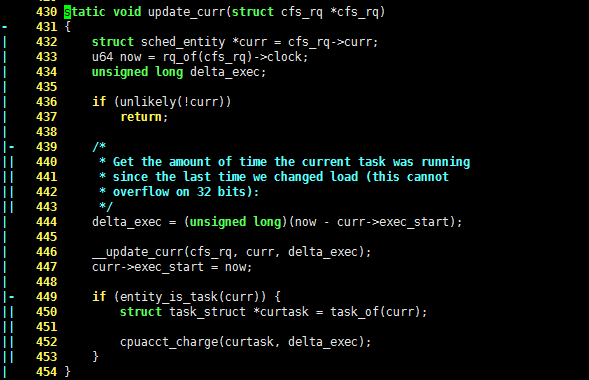
现在知道了 linux 的时间账本记录在哪里了,那么谁负责记账呢?其实就是 update_curr() 函数了,它的代码如下,请看:
430 static void update_curr(struct cfs_rq *cfs_rq)
- 431 {
| 432 struct sched_entity *curr = cfs_rq->curr;
| 433 u64 now = rq_of(cfs_rq)->clock;
| 434 unsigned long delta_exec;
| 435
| 436 if (unlikely(!curr))
| 437 return;
| 438
|- 439 /*
|| 440 * Get the amount of time the current task was running
|| 441 * since the last time we changed load (this cannot
|| 442 * overflow on 32 bits):
|| 443 */
| 444 delta_exec = (unsigned long)(now - curr->exec_start);
| 445
| 446 __update_curr(cfs_rq, curr, delta_exec);
| 447 curr->exec_start = now;
| 448
|- 449 if (entity_is_task(curr)) {
|| 450 struct task_struct *curtask = task_of(curr);
|| 451
|| 452 cpuacct_charge(curtask, delta_exec);
|| 453 }
| 454 }
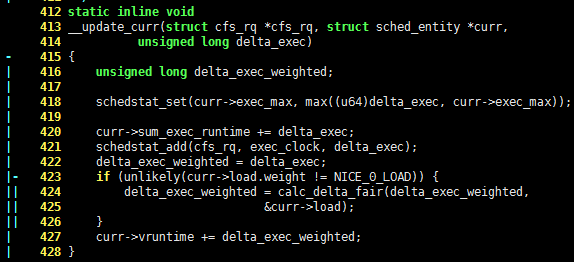
412 static inline void
413 __update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr,
414 unsigned long delta_exec)
- 415 {
| 416 unsigned long delta_exec_weighted;
| 417
| 418 schedstat_set(curr->exec_max, max((u64)delta_exec, curr->exec_max));
| 419
| 420 curr->sum_exec_runtime += delta_exec;
| 421 schedstat_add(cfs_rq, exec_clock, delta_exec);
| 422 delta_exec_weighted = delta_exec;
|- 423 if (unlikely(curr->load.weight != NICE_0_LOAD)) {
|| 424 delta_exec_weighted = calc_delta_fair(delta_exec_weighted,
|| 425 &curr->load);
|| 426 }
| 427 curr->vruntime += delta_exec_weighted;
| 428 }
进程调度,让每个进程都有相对公平的机会运行
现在 cfs 已经知道每个进程的执行状况了,那么挑选哪个进程投入运行呢?答案是显而易见的,cfs 为了给每个进程相对公平的机会运行,总是挑选具有最小 vruntime 的进程。
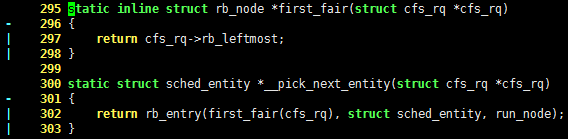
为了快速找到拥有 vruntime 的进程,linux 内核借用了红黑树的数据结构。最小的 vruntime 总是在树的最左侧叶子节点,请看如下代码:
295 static inline struct rb_node *first_fair(struct cfs_rq *cfs_rq)
- 296 {
| 297 return cfs_rq->rb_leftmost;
| 298 }
299
300 static struct sched_entity *__pick_next_entity(struct cfs_rq *cfs_rq)
- 301 {
| 302 return rb_entry(first_fair(cfs_rq), struct sched_entity, run_node);
| 303 }
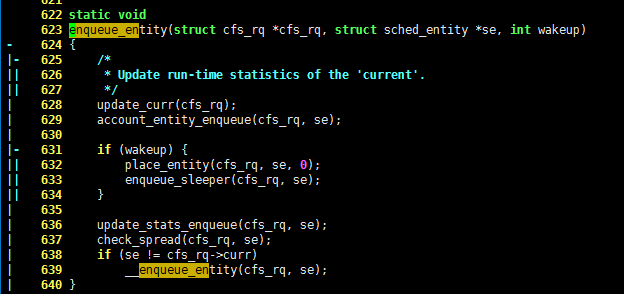
看到这里,知道 linux 内核在往树中加入进程时,就应该将树处理好,这一过程由 enqueue_entity 函数完成:
622 static void
623 enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int wakeup)
- 624 {
|- 625 /*
|| 626 * Update run-time statistics of the 'current'.
|| 627 */
| 628 update_curr(cfs_rq);
| 629 account_entity_enqueue(cfs_rq, se);
| 630
|- 631 if (wakeup) {
|| 632 place_entity(cfs_rq, se, 0);
|| 633 enqueue_sleeper(cfs_rq, se);
|| 634 }
| 635
| 636 update_stats_enqueue(cfs_rq, se);
| 637 check_spread(cfs_rq, se);
| 638 if (se != cfs_rq->curr)
| 639 __enqueue_entity(cfs_rq, se);
| 640 }
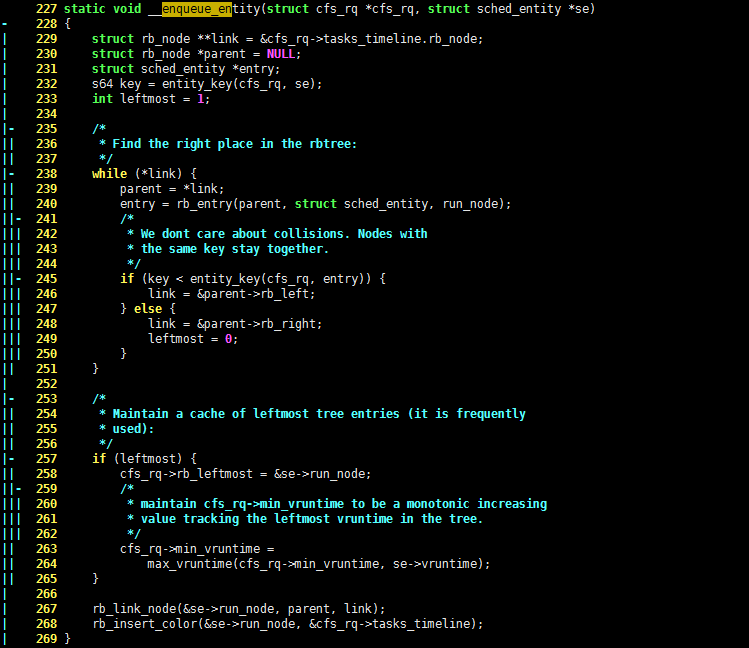
227 static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
- 228 {
| 229 struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;
| 230 struct rb_node *parent = NULL;
| 231 struct sched_entity *entry;
| 232 s64 key = entity_key(cfs_rq, se);
| 233 int leftmost = 1;
| 234
|- 235 /*
|| 236 * Find the right place in the rbtree:
|| 237 */
|- 238 while (*link) {
|| 239 parent = *link;
|| 240 entry = rb_entry(parent, struct sched_entity, run_node);
||- 241 /*
||| 242 * We dont care about collisions. Nodes with
||| 243 * the same key stay together.
||| 244 */
||- 245 if (key < entity_key(cfs_rq, entry)) {
||| 246 link = &parent->rb_left;
||| 247 } else {
||| 248 link = &parent->rb_right;
||| 249 leftmost = 0;
||| 250 }
|| 251 }
| 252
|- 253 /*
|| 254 * Maintain a cache of leftmost tree entries (it is frequently
|| 255 * used):
|| 256 */
|- 257 if (leftmost) {
|| 258 cfs_rq->rb_leftmost = &se->run_node;
||- 259 /*
||| 260 * maintain cfs_rq->min_vruntime to be a monotonic increasing
||| 261 * value tracking the leftmost vruntime in the tree.
||| 262 */
|| 263 cfs_rq->min_vruntime =
|| 264 max_vruntime(cfs_rq->min_vruntime, se->vruntime);
|| 265 }
| 266
| 267 rb_link_node(&se->run_node, parent, link);
| 268 rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);
| 269 }
至此,linux 内核中经典的 cfs 进程调度设计,就比较熟悉了。