linux下的C开发10,I/O函数的数据结构
发表于: 2019-01-06 13:52:51 | 已被阅读: 980 | 分类于: Linux笔记
上一节介绍了 linux 中 C语言常用的“不带缓冲”的 I/O 函数组,并在文章最后举了一个读写文件的例子。通过例子,我们知道了 linux 内核会在读写文件时,记录文件的当前偏移量。

那么,linux 内核读写文件时,是在哪里记录的偏移量呢?而且,上一节的示例是在同一个进程中打开的同个文件,不同的进程能否共享同一个文件呢?不同的进程读写文件,偏移量会互相影响吗?本节将讨论这些问题。
linux 内核 I/O C语言函数采用的数据结构
首先先说结论:linux 系统是支持不同进程共享同一个文件的。在我之前的《linux学习系列》文章里,曾经说过,linux 内核会使用巨大的 task_struct 结构体记录每一个进程持有哪些资源等信息,其中,文件描述表就包含在这些进程持有的资源中。
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
int lock_depth; /* BKL lock depth */
...
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
...
使用 open 打开文件时,返回 fd 其实是与文件描述符表对应的。文件表包含文件的状态标志位(只读、只写、读写、阻塞等),当前文件的偏移量,以及 i 节点指针。其中,i 节点指针指向一个结构体,这个结构体包含一系列用于操作函数的函数指针,以及文件长度等信息。文件的所有者,指向文件实际数据块在磁盘中的位置指针等信息,也包含在 i 节点表里。
linux 内核采用大量 C语言和少量汇编语言编写,因为 C语言并不支持类的定义,所以 linux 内核使用结构体模拟了类,使用结构体中的函数指针模拟了类的成员函数。这其实是面向对象思想的灵活运用。
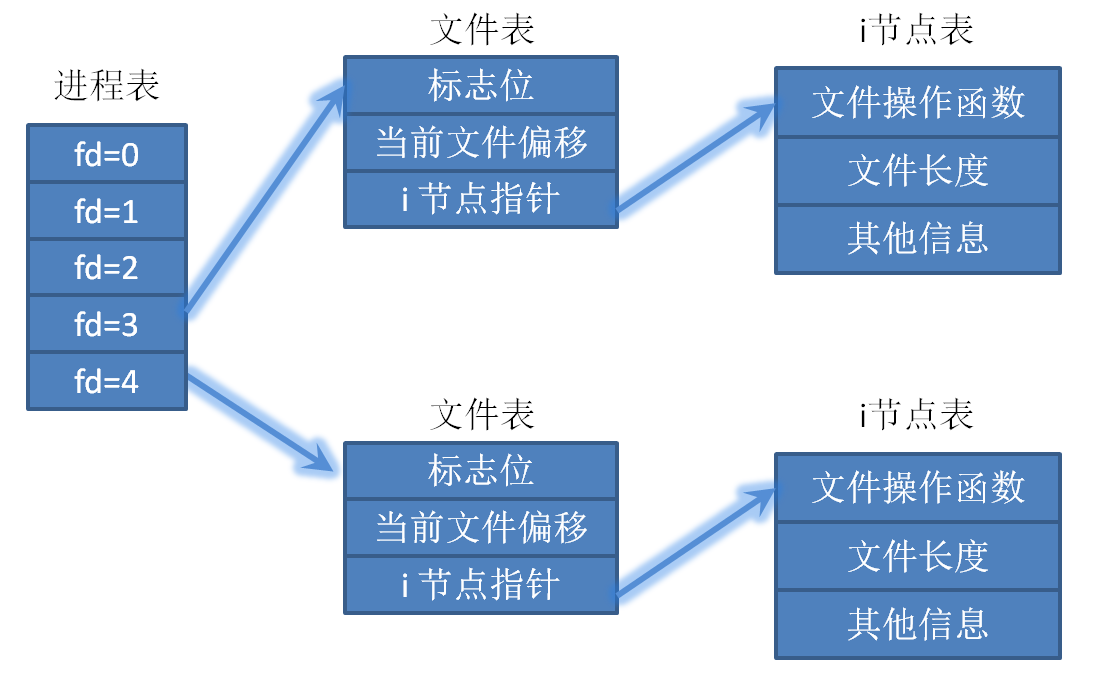
多个进程打开同一个文件
进程A和进程B同时调用 open 函数打开了同一个文件,如下图,假设进程A的 open 函数返回值为 3,进程B调用 open 函数返回值为 4。linux 内核会为进程A和进程B分别分配一个独立的文件表,但是这两个文件表的 i 节点指针会指向同一个 i 节点表项。
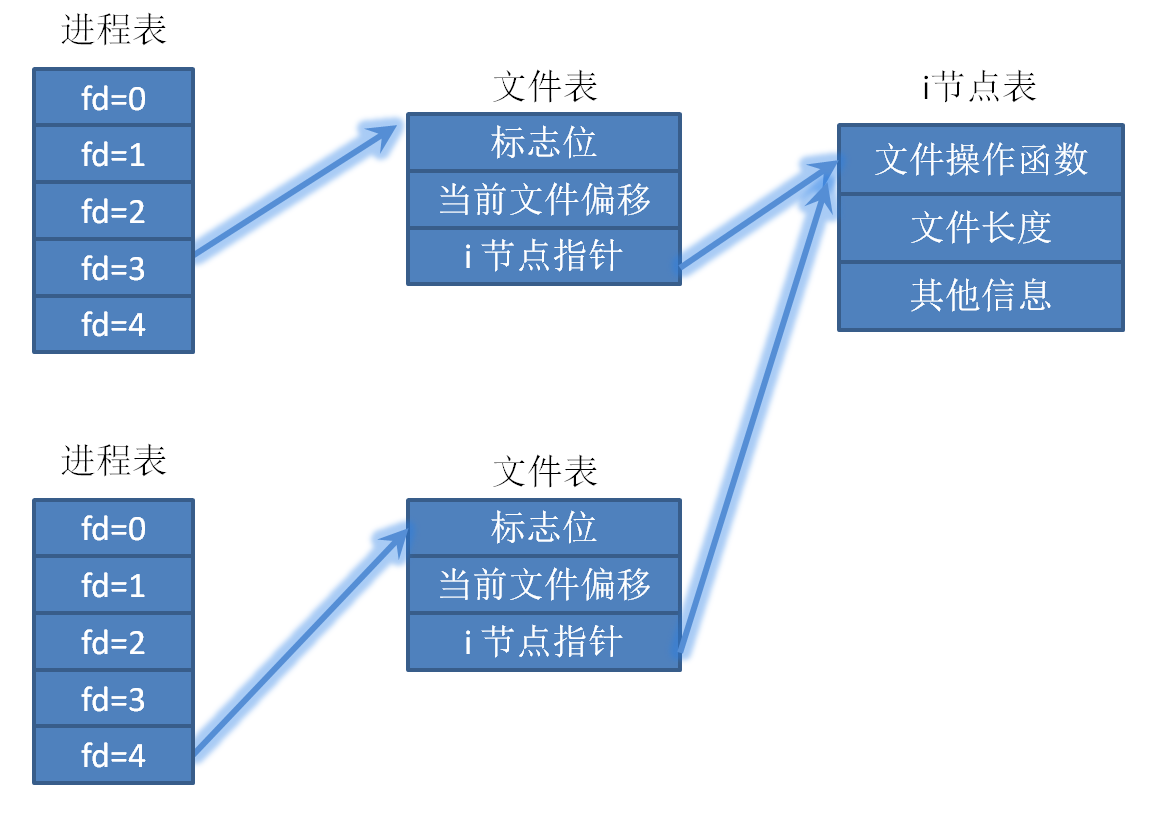
因为进程A和进程B打开的是同一个文件,它俩的 i 节点表项肯定是一样的,所以两个文件表的 i 节点指针指向同一个 i 节点表项不难理解。
而由于每个都拥有各自的文件表,因此每个进程记录的当前文件偏移可能并不一致,多个进程同时写一个文件,就有可能产生预想不到的结果,为了避免这种情况,需要理解原子操作的概念。这点,我们下一节再讨论。

进一步说明
在了解了 linux 内核 I/O C语言函数采用的数据结构后,现在对 I/O 函数做进一步说明:
- write 函数写入数据后,文件表中记录的当前文件偏移量增加写入的字节数。如果当前文件偏移量超出了当前文件长度,则将 i 节点表项中的当前文件长度置为当前偏移量。看起来,就好像文件的大小变大了。
- 如果使用 open 函数打开文件时,传入了 O_APPEND(附加)标志位参数,则文件表中记录的标志位也做相应修改。而且,这时 write 函数写入时,文件表中的当前偏移量会首先被设置为 i 节点表记录的文件长度。看起来,就好像每次写入数据都从文件最后开始写。
- lseek 函数只修改文件表项中记录的当前文件偏移量,并没有实际的 I/O 操作。