linux学习19,内核中的“队列”数据类型
发表于: 2019-01-22 19:43:46 | 已被阅读: 787 | 分类于: Linux笔记
前面两节较为详细的讨论了 linux 内核中链表的设计,以及相关的C语言代码实现。本节再来看看 linux 内核中另外一种常用的数据类型:队列。
“队列”数据结构适合处理“生产者”和“消费者”编程模型
事实上,不仅仅是 linux 内核,基本上稍微有些规模的编程项目都会用到“队列”的概念。队列这种数据结构特别适合处理“生产者”和“消费者”编程模型。

生产者产生数据。比如麦克风设备产生的音频数据,从网络传来的tcp数据等。这些数据大都不能在产生的时候“瞬间”被处理完成,一般都会被暂时放在内存里。消费者则负责处理这些数据,比如从麦克风设备读取音频数据保存到磁盘,从网络读取 tcp 数据分析等。
实现“生产者”和“消费者”编程模型的最佳数据结构无疑是“队列”。所谓队列,其实就是“拍好队的数据”而已。生产者将数据推入队列,消费者则从队列头挨个摘取数据处理,如此一来,第一个进入队列的数据肯定会被消费者第一个处理。

C语言中的“队列”和现实世界中人类排队是相似的,都是谁先在队伍里排队,谁的事就最先被处理,所以“队列”也被称为 FIFO(first in first out, 先进先出)。
linux 内核中“队列”数据结构的设计,以及相关C语言代码实现
linux 内核使用的“队列”设计相当简洁,实际上,内核中关于队列(kfifo)的代码量只有数百行。下面介绍一下 linux 内核中的队列,请看下面的 C语言代码:
struct kfifo {
unsigned char *buffer; /* the buffer holding the data */
unsigned int size; /* the size of the allocated buffer */
unsigned int in; /* data is added at offset (in % size) */
unsigned int out; /* data is extracted from off. (out % size) */
spinlock_t *lock; /* protects concurrent modifications */
};

struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock)
{
unsigned char *buffer;
struct kfifo *ret;
/*
* round up to the next power of 2, since our 'let the indices
* wrap' tachnique works only in this case.
*/
if (size & (size - 1)) {
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size);
}
buffer = kmalloc(size, gfp_mask);
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock);
if (IS_ERR(ret))
kfree(buffer);
return ret;
}

struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
gfp_t gfp_mask, spinlock_t *lock)
{
struct kfifo *fifo;
/* size must be a power of 2 */
BUG_ON(!is_power_of_2(size));
fifo = kmalloc(sizeof(struct kfifo), gfp_mask);
if (!fifo)
return ERR_PTR(-ENOMEM);
fifo->buffer = buffer;
fifo->size = size;
fifo->in = fifo->out = 0;
fifo->lock = lock;
return fifo;
}
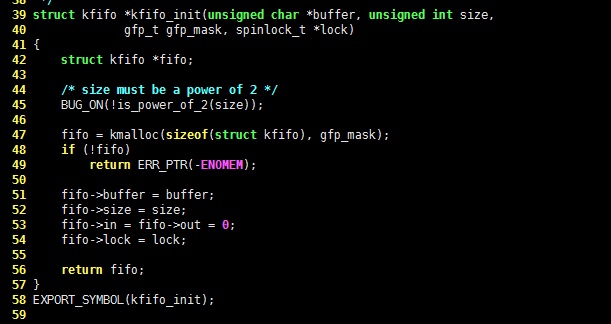

不难看出,out 总是小于或者等于 in。
推入队列数据
linux 内核往队列推入数据的动作由 kfifo_put() 函数完成,它的C语言代码如下,请看:
79 static inline unsigned int kfifo_put(struct kfifo *fifo,
80 unsigned char *buffer, unsigned int len)
- 81 {
| 82 unsigned long flags;
| 83 unsigned int ret;
| 84
| 85 spin_lock_irqsave(fifo->lock, flags);
| 86
| 87 ret = __kfifo_put(fifo, buffer, len);
| 88
| 89 spin_unlock_irqrestore(fifo->lock, flags);
| 90
| 91 return ret;
| 92 }
核心代码是
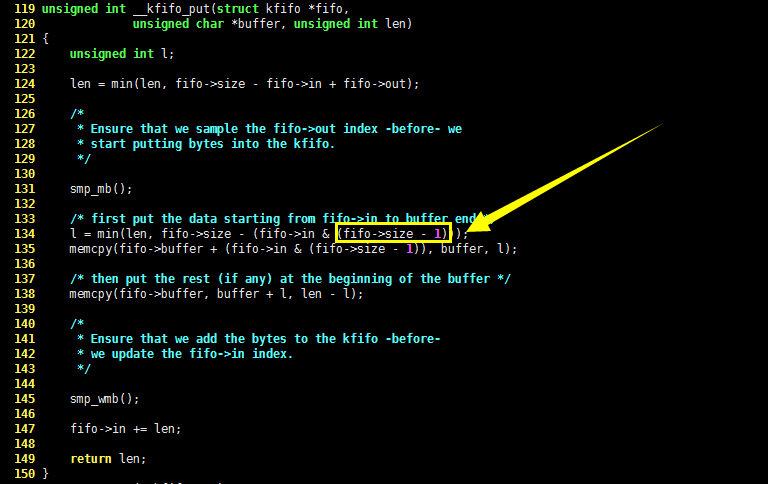


继续分析 kfifo_put() 函数,数据可能会被截成两段放入 buffer。什么时候被截成两段呢?请看下图:
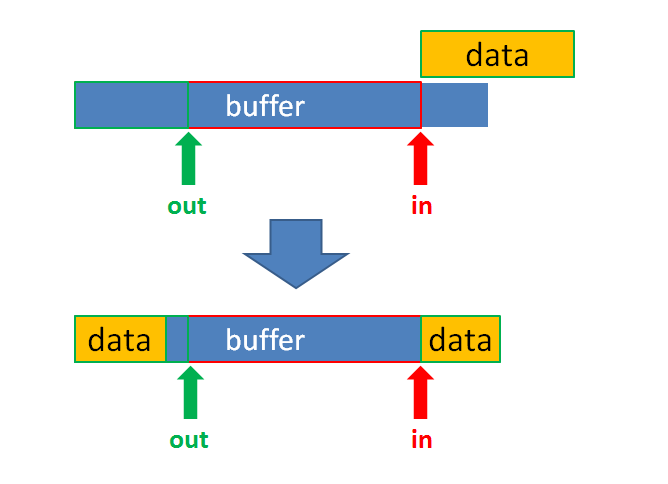
摘取队列数据
往队列推入数据可以调用 kfifo_put() 函数,那么从队列摘取数据则可以用 kfifo_get() 函数,它的C语言代码如下:
103 static inline unsigned int kfifo_get(struct kfifo *fifo,
104 unsigned char *buffer, unsigned int len)
- 105 {
| 106 unsigned long flags;
| 107 unsigned int ret;
| 108
| 109 spin_lock_irqsave(fifo->lock, flags);
| 110
| 111 ret = __kfifo_get(fifo, buffer, len);
| 112
| 113 /*
| 114 * optimization: if the FIFO is empty, set the indices to 0
| 115 * so we don't wrap the next time
| 116 */
| 117 if (fifo->in == fifo->out)
| 118 fifo->in = fifo->out = 0;
| 119
| 120 spin_unlock_irqrestore(fifo->lock, flags);
| 121
| 122 return ret;
| 123 }
同样的,核心代码是

重置队列
如果不再需要队列中的数据,并且希望重复使用队列,则简单重置 fifo->in 与 fifo->out 即可:
static inline void __kfifo_reset(struct kfifo *fifo)
{
fifo->in = fifo->out = 0;
}
可以看出,这种设计相当简洁。